ZapDoc is an AI-powered document processing platform that extracts structured data from PDF documents and delivers results in Excel format via email.
I didn’t start out wanting to build a document automation platform.
What I wanted was leverage. I’d seen firsthand how time-consuming and painful it was to pull structured data out of messy PDFs: invoices, CVs, contracts, proposals… all needing to be manually parsed, copy-pasted, or hand-entered into Excel.
So I asked myself: Could I build something that turns these documents into clean, structured spreadsheets, with zero effort from the user?
After a few weekends and sleepless nights, the answer became ZapDoc, a web tool that:
Takes multiple PDFs or a .zip archive,
Lets you define which fields you want to extract (e.g. “name”, “email”, “amount”, “date”),
And returns a clean Excel file by email.
It sounds simple, but the devil is in the details.
From MVP to modular system
I built the first prototype over a weekend: FastAPI for the backend, hosted on Railway; a minimal React frontend on Vercel; and OpenAI for field extraction.
v0: prove it works
The early version was rough, but functional.
The idea was to make it free, so people would actually use it and I’d get some feedback. It had to be friction-free.
I tested it with real CVs and invoices. I posted in indie Discords to get feedback, asking people what they’d actually use it for.
One thing became clear: I didn’t need to support every document type. I needed to be amazing at just a few — like resumes, invoices, and RFPs.
Iterating
v1:
.zip upload support
Field templates (e.g., pre-fill “name” and “email” for resumes)
Date formatting, better validation
v2:
Usage analytics (without storing docs)
Email capture → no sign up yet, but I you’d still need to give your e-mail address
Templates for RFPs and proposals
v3:
Auth system + Supabase-backed user DB
Credit management service
Payment flow & webhook integration
A cleaner, more secure pipeline
Every iteration made it more robust, less hacky, and closer to a real SaaS.
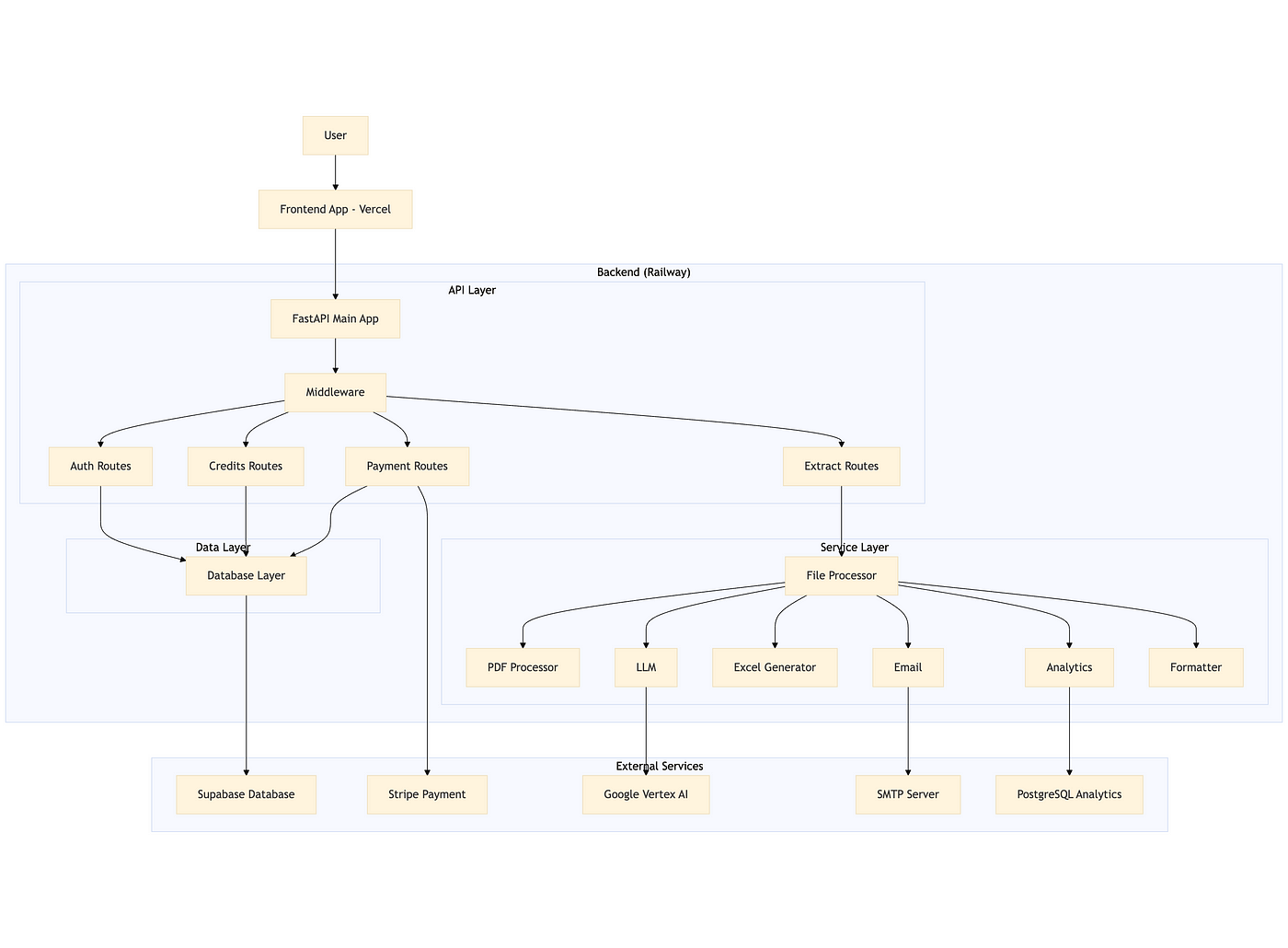
System Architecture (v3 overview)
ZapDoc consists of a Vercel-hosted frontend and a Railway-hosted FastAPI backend.
The core value proposition is simple: upload PDF documents, specify which fields you want to extract, and receive structured data in Excel format via email.
Overview of the system design
Technical Stack
Backend: FastAPI (Python) running on Railway
AI: Google Vertex AI (Gemini)
Database: Supabase (PostgreSQL)
Payments: Stripe
Frontend: React (Vercel)
Analytics: PostgreSQL
Core Implementation
1. FastAPI app
The backend is modular, with clear separation between API routes, services, and data models.
Middleware enforces CORS and HTTPS, and all routes are grouped by function (auth, extract, credits, payment).
2. Authentication & authorization
Authentication is handled via Supabase JWT tokens. The backend validates tokens on every request using a dependency-injected function, ensuring only authenticated users can access protected endpoints.
3. Document processing pipeline
Credit validation
Before processing, the system checks if the user has enough credits (1 credit per page). This is done atomically to prevent race conditions, using asyncio locks and optimistic locking at the database level.
Page counting
The backend counts the total number of pages across all uploaded PDFs and ZIPs (containing PDFs) using PyPDF.
PDF text extraction
Text is extracted from each PDF using PyPDF, with robust error handling for malformed or encrypted files.
AI-powered field extraction
The extracted text is sent to Google Vertex AI (or OpenAI as fallback) with a prompt to extract only the requested fields. The response is parsed and validated, using the json_repair library to handle malformed JSON.
Document classification
For analytics, the document is also classified (invoice, receipt, contract, etc.) using the same LLM service.
Excel generation
Extracted data is written to an Excel file using OpenPyXL, with the first row as headers and subsequent rows as data.
A header column is included, with the file names.
Email delivery
The resulting Excel file is sent to the user via SMTP, using a styled HTML template and proper attachment handling.
4. Atomic credit operations
All credit operations (add/spend) are atomic. The backend uses asyncio locks and checks the current credit balance before updating, retrying if a concurrent modification is detected.
5. Payment integration
Stripe is used for purchasing credits. The backend creates a checkout session and listens for webhook events to credit the user’s account after successful payment.
6. Analytics
The processed documents themselves are not stored, but the type (resume, etc.) and status (error / success) is logged to a PostgreSQL analytics database for monitoring and future insights.
Key technical challenges & solutions
By far, the most challenging part for me was setting up the whole thing in a way that it wouldn’t have major security flaws.
In short, when I set the credit/payment part, I wanted to make sure that users couldn’t bypass the payment system somehow, nor get other users’ email addresses.
Since this is the part I’m the least comfortable with, I had a lot of help from ChatGPT.
Things like path traversal protection, user isolation, CORS, middleware, etc. are still not 100% clear to me, but this project helped me get a better understanding of them.
Some other stuff to keep in mind
Race conditions: Solved with asyncio locks and optimistic DB updates.
LLM response robustness: Used json_repair and strict field validation.
PDF extraction reliability: PyPDF with error handling and support for ZIPs.
Performance: Async I/O, efficient batch processing, and proper resource cleanup.
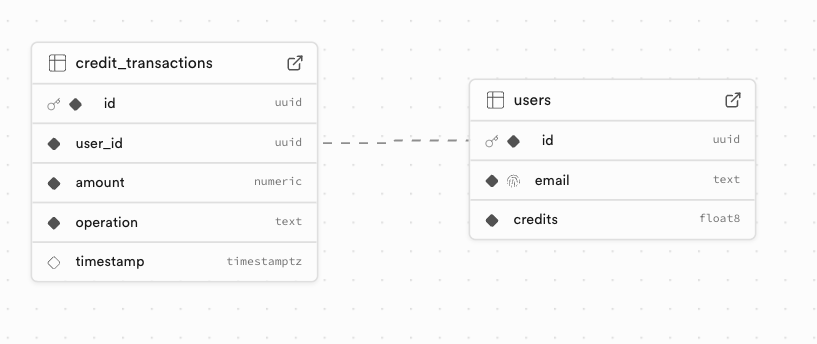
Database Schema (Supabase)
Branding, naming & launch
I wanted something simple, memorable, and descriptive.
After a few brainstorms, I landed on ZapDoc, because it zaps your documents into structured data.
The name stuck.
I described the project to ChatGPT and asked it to draw a logo.
Its first suggestion wasn’t amazing, but it was good enough, so I kept it:
Then came the social and launch planning: Medium, LinkedIn, X, Bluesky, Discord, Uneed, Product Hunt… I’m still rolling that out now.
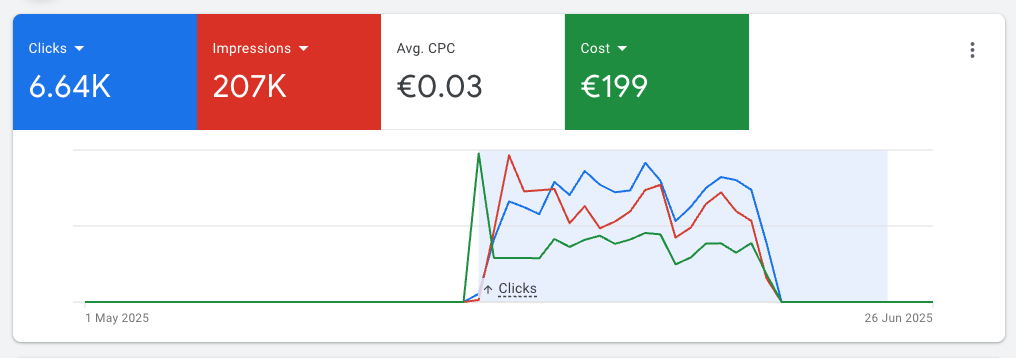
To get some validation for the product, I launched this free version and even ran some Google Ads campaigns for it (~200 euros over 3 weeks)
That brought a lot of people to the tool, but not many users:
Plus, I saw that once the ads stopped, traffic was basically over.
This indicates that people who tried it before didn’t really stick to it.
Either the tool is not useful, or I’m not reaching the right people.
What I learned (so far)
Start with a niche: you can’t beat GPT-4 at “generic doc parsing”, but you can win at “extract line items from French invoices”.
Atomicity matters: especially when money is involved.
AI output isn’t perfect: you need robust validation & formatting layers.
Building is much easier than selling: it became much easier to build powerfull tools with the help of AI. Making people pay for them is much harder than I expected.
To be honest, I’m still struggling with the niche part: from the usage stats, it seems that most people use it to parse CVs (I thought it would be contracts). But that’s still too generic, so I’ll try to narrow it down once I get more usage data.
What’s next
For v4 and beyond, I’ll try to run ads again (but put less money this time), to see if now people are willing to actually sign up and pay.
If that happens, then I’ll work on some more technical improvements. Some ideas I have in mind for this:
Move logs from Railway to Supabase for better observability
Expose an API, so people can integrate it into their own tools
Add more document types (contracts, tenders)
Allow users to store custom lists of fields
Final thoughts
ZapDoc is still small.
But it works, and it helped me learn a lot of useful stuff.
Now, I want to crack the sales part, so I can help real users automate real work.
If you’re building with LLMs, don’t chase the hype. Solve a boring problem really well.
Use Hugging Face’s smolagents framework to automate customer support for a fashion store
Introduction
Fashion retailers receive hundreds of customer emails every day.
Some asking about products, others trying to place orders. Manually handling these messages is time-consuming, error-prone, and doesn’t scale.
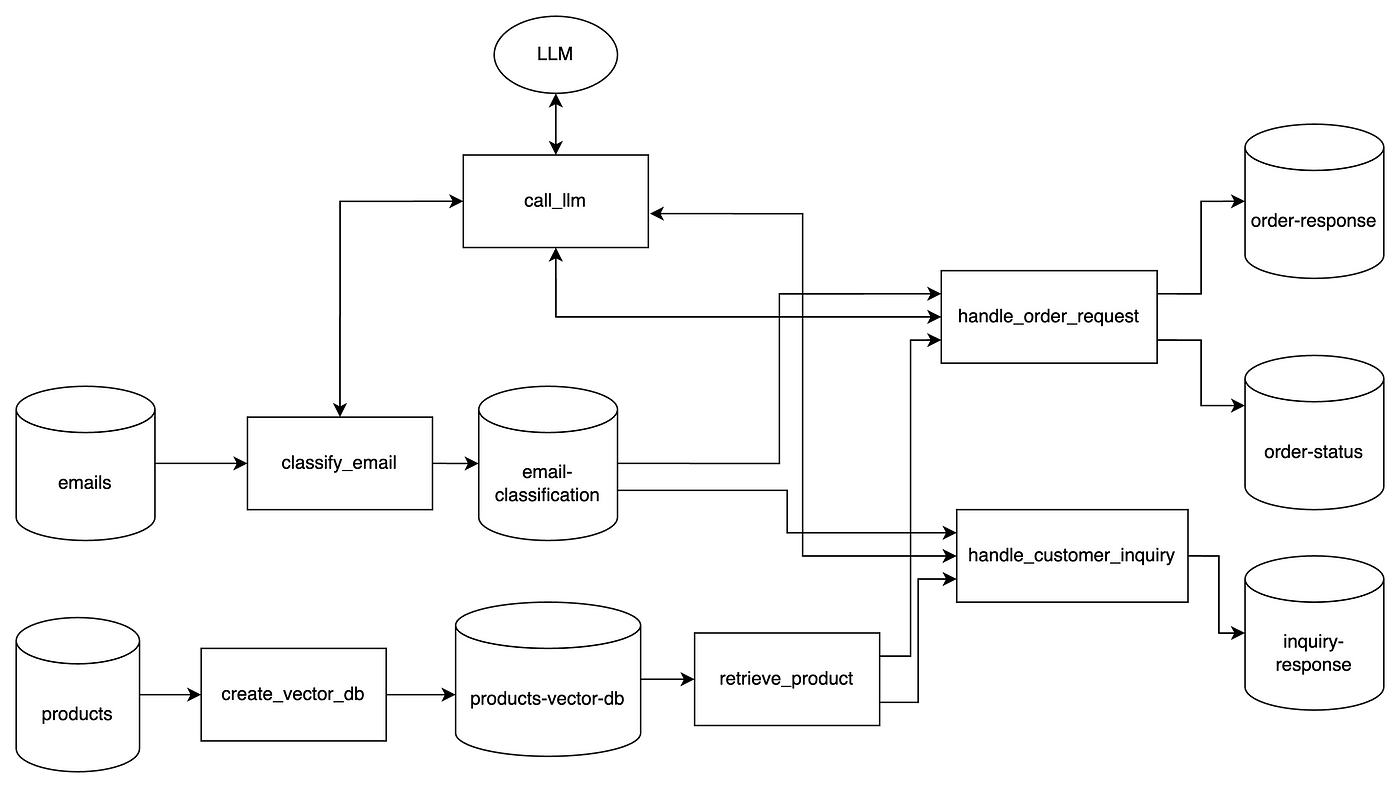
In this project, we tackle this problem by building an AI system that reads emails, classifies their intent, and automatically generates appropriate responses.
We will embed product data using OpenAI, and store the vectors in ChromaDB. It’s a good choice for fast retrieval and setup, keeping things local.
One very important feature here is metadata: we need to make sure this is properly set for enhanced search. For instance, ChromaDB doesn’t handle well filters on array fields, so we turn the “seasons” field into a set of boolean columns.
import chromadb from chromadb.config import Settings from chromadb.errors import NotFoundError
Now, to the juicy part: setting up our agent and it’s tool.
Since we needs to be able to query our product database, we create a function called query_product_db, which takes as input a query and filters.
For it to be a proper tool, our function needs the @tool decorator, a proper docstring, and type hints. This is what allows our agent to know exactly how to use.
In our case, we need our agent to know exactly how to use the metadata filters in ChromaDB, so setting up a few examples is a good idea:
from smolagents import OpenAIServerModel, ToolCallingAgent, tool from typing import List, Optional
@tool def query_product_db(query: str, metadata_filter:dict | None=None, document_filter:dict | None=None) -> dict: """Retrieve the three best-matching products from the `products` Chroma DB vectorstore.
Args: query : str Natural-language search term. A dense vector is generated with ``get_embedding`` and used for similarity search. metadata_filter : dict | None, optional A Chroma metadata filter expressed with Mongo-style operators (e.g. ``{"$and": [{"price": {"$lt": 25}}, {"fall": {"$eq": 1}}]}``). If *None*, no metadata constraints are applied. document_filter : dict | None, optional Full-text filter run on each document’s contents (e.g. ``{"$contains": "scarf"}``). If *None*, every document is eligible.
Examples -------- >>> get_product( ... "a winter accessory under 25 dollars, the id is FZZ1098", ... metadata_filter={ ... "$and": [ ... {"price": {"$lt": 25}}, ... {"category": {"$in": ["Accessories"]}}, ... {"winter": {"$eq": 1}}, {"product_id""{"$eq": "FZZ1098"}} ... ] ... }, ... document_filter={"$contains": "scarf"} ... )
Here's an overview of the product database metadata:
product_id,name,category,description,stock,spring,summer,fall,winter,price RSG8901,Retro Sunglasses,Accessories,"Transport yourself back in time with our retro sunglasses. These vintage-inspired shades offer a cool, nostalgic vibe while protecting your eyes from the sun's rays. Perfect for beach days or city strolls.",1,1,1,0,0,26.99 SWL2345,Sleek Wallet,Accessories,"Keep your essentials organized and secure with our sleek wallet. Featuring multiple card slots and a billfold compartment, this stylish wallet is both functional and fashionable. Perfect for everyday carry.",5,1,1,0,0,30 VSC6789,Versatile Scarf,Accessories,"Add a touch of versatility to your wardrobe with our versatile scarf. This lightweight, multi-purpose accessory can be worn as a scarf, shawl, or even a headwrap. Perfect for transitional seasons or travel.",6,1,0,1,0,23
Finally, we use ToolCallingAgent, which is suited for our use case.
In some other cases, you might want to use CodeAgent (for example, for writing code, obviously).
4. Email classification with LLM
Next step is to ese GPT to classify each email as either an “order request” or “product inquiry” and store results in an email-classification dataframe.
For this we don’t need the agent: a simple call to an LLM is enough:
from pydantic import BaseModel, Field from typing import Literal
class EmailClass(BaseModel): category: Literal["order_request", "customer_inquiry"] = Field(..., description="Email classification")
def classify_email(email): system_prompt = """You are a smart classifier trained to categorize customer emails based on their content. Each email includes a subject and a message body. There are two possible categories: • order_request: The customer is clearly expressing the intent to place an order, make a purchase, or asking to buy something (even if casually or imprecisely). • customer_inquiry: The customer is asking a question, requesting information, or needs help deciding before buying.
Classify the following emails based on their subject and message. Output only one of the two categories: order_request or customer_inquiry. Do not add any extra text, just the class.
⸻
Examples:
Email 1 Subject: Leather Wallets Message: Hi there, I want to order all the remaining LTH0976 Leather Bifold Wallets you have in stock. I’m opening up a small boutique shop and these would be perfect for my inventory. Thank you! Category: order_request
Email 2 Subject: Need your help Message: Hello, I need a new bag to carry my laptop and documents for work. My name is David and I’m having a hard time deciding which would be better - the LTH1098 Leather Backpack or the Leather Tote? Does one have more organizational pockets than the other? Category: customer_inquiry
Email 3 Subject: Purchase Retro Sunglasses Message: Hello, I would like to order 1 pair of RSG8901 Retro Sunglasses. Thanks! Category: order_request
Email 4 Subject: Inquiry on Cozy Shawl Details Message: Good day, For the CSH1098 Cozy Shawl, the description mentions it can be worn as a lightweight blanket. At $22, is the material good enough quality to use as a lap blanket? Category: customer_inquiry """
user_prompt = f""" Now classify this email: Subject: {email.subject} Message: {email.message} Category: """
Now that everything is set up, let’s handle our first use case: dealing with order requests.
These emails can be tricky they might mention a certain product by its name, ID, or something else. They might mention the quantity they want to buy, or things like “all you have in stock”.
For ex.:
Subject: Leather Wallets Message: Hi there, I want to order all the remaining LTH0976 Leather Bifold Wallets you have in stock. I'm opening up a small boutique shop and these would be perfect for my inventory. Thank you!
So, before we deal with it, we need to extract product requests from emails using structured LLM prompts. For instance, product id and requested quantity. Since quantity might be “all you have in stock”, our agent needs access to the product database to find that information.
Extract structured information
Let’s start extracting structured information from the email, using our agent:
def extract_order_request_info(order_request): prompt = f""" Given a customer email placing a product order, extract the relevant information from it: product and quantity. The customer might mention multiple products, but we only need those for which they are explictly placing an order.
answer should be in this format: [{{'product_id': <the product ID, in this format: 'VSC6789'>,'quantity': <an integer>}}] 'quantity' should always be an integer. If needed, check the quantity in stock. If the mentioned product ID does not follow that format (ex.: it contains spaces, '-', etc.), clean it to follow that format (3 letters, 4 numbers, no other characters)
Here are 2 examples of the expected output: Example 1: [{{'product_id': 'LTH0976', 'quantity': 4}}]
Example 2: [{{'product_id': 'SFT1098', 'quantity': 3}}, {{'product_id': 'ABC1234', 'quantity': 1}}]
╭──────────────────────────────────────────────────── New run ────────────────────────────────────────────────────╮ │ │ │ Given a customer email placing a product order, extract the relevant information from it: product and quantity. │ │ The customer might mention multiple products, but we only need those for which they are explictly │ │ placing an order. │ │ │ │ │ │ Subject: Leather Wallets │ │ Message: Hi there, I want to order all the remaining LTH0976 Leather Bifold Wallets you have in stock. │ │ I'm opening up a small boutique shop and these would be perfect for my inventory. Thank you! │ │ │ │ answer should be in this format: │ │ [{'product_id': <the product ID, in this format: 'VSC6789'>,'quantity': <an integer>}\] │ │ 'quantity' should always be an integer. If needed, check the quantity in stock. │ │ If the mentioned product ID does not follow that format (ex.: it contains spaces, '-', etc.), │ │ clean it to follow that format (3 letters, 4 numbers, no other characters) │ │ │ │ │ │ │ │ Here are 2 examples of the expected output: │ │ Example 1: │ │ [{'product_id': 'LTH0976', 'quantity': 4}\] │ │ │ │ Example 2: │ │ [{'product_id': 'SFT1098', 'quantity': 3}, {'product_id': 'ABC1234', 'quantity': 1}\] │ │ │ ╰─ OpenAIServerModel - gpt-4o ────────────────────────────────────────────────────────────────────────────────────╯ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ Step 1 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ ╭─────────────────────────────────────────────────────────────────────────────────────────────────────────────────╮ │ Calling tool: 'query_product_db' with arguments: {'query': 'LTH0976 Leather Bifold Wallet'} │ ╰─────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯ Observations: {'ids': ||'5', '1', '21']], 'embeddings': None, 'documents': ||'Leather Bifold Wallet Accessories Upgrade your everyday carry with our leather bifold wallet. Crafted from premium, full-grain leather, this sleek wallet features multiple card slots, a billfold compartment, and a timeless, minimalist design. A sophisticated choice for any occasion. All seasons', 'Sleek Wallet Accessories Keep your essentials organized and secure with our sleek wallet. Featuring multiple card slots and a billfold compartment, this stylish wallet is both functional and fashionable. Perfect for everyday carry. All seasons', 'Leather Backpack Bags Upgrade your daily carry with our leather backpack. Crafted from premium leather, this stylish backpack features multiple compartments, a padded laptop sleeve, and adjustable straps for a comfortable fit. Perfect for work, travel, or everyday use. All seasons']], 'uris': None, 'included': |'documents', 'metadatas', 'distances'], 'data': None, 'metadatas': ||{'fall': 1, 'winter': 1, 'summer': 1, 'stock': 4, 'price': 21.0, 'category': 'Accessories', 'spring': 1, 'product_id': 'LTH0976'}, {'fall': 1, 'spring': 1, 'winter': 1, 'price': 30.0, 'category': 'Accessories', 'stock': 5, 'summer': 1, 'product_id': 'SWL2345'}, {'fall': 1, 'summer': 1, 'price': 43.99, 'product_id': 'LTH1098', 'category': 'Bags', 'stock': 7, 'spring': 1, 'winter': 1}]], 'distances': ||0.7475106716156006, 1.036144733428955, 1.1911123991012573]]} [Step 1: Duration 3.41 seconds| Input tokens: 1,710 | Output tokens: 23] ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ Step 2 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ ╭─────────────────────────────────────────────────────────────────────────────────────────────────────────────────╮ │ Calling tool: 'final_answer' with arguments: {'answer': "[{'product_id': 'LTH0976', 'quantity': 4}]"} │ ╰─────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
We can see it using the query_product_db tool and reflecting on its output (for example, if the requested quantity is in stock).
Process order
With the structured order information in hands, we can process those orders:
for _, row in exploded_order_requests_df.iterrows(): email_id = row['email_id'] product_id = row['product_id'] quantity = row['quantity']
if product_id in products.index: available_stock = products.at[product_id, 'stock']
if available_stock >= quantity: status = 'created' products.at[product_id, 'stock'] -= quantity else: status = 'out of stock' else: status = 'out of stock'
And, finally, use an LLM to generate a human-like response: confirm or explain stock issues, suggest alternatives.
def write_order_request_response(message, order_status): system_prompt = f""" A customer has requested to place an order for a product. Write a response to them, stating if the order was created or not, and reinforcing the product and the quantity ordered. If it was out of stock, explain it to them.
Make the email tone professional, yet friendly. You should sound human so, if the customer mentions something in their email that's worth referring to, do it.
Do not add any other text, such as email subject or placeholders, just a clean email body. Here are 2 examples of the expected reply:
Example 1: 'Hi there, Thank you for reaching out and considering our LTH0976 Leather Bifold Wallets for your new boutique shop. We’re thrilled to hear about your exciting venture! Unfortunately, the LTH0976 Leather Bifold Wallets are currently out of stock. We sincerely apologize for any inconvenience this may cause. Please let us know if there’s anything else we can assist you with or if you’d like to explore alternative products that might suit your boutique. Best, Customer Support'
Example 2: 'Hi, Thank you for reaching out and sharing your love for tote bags! It sounds like you have quite the collection! I'm pleased to inform you that your order for the VBT2345 Vibrant Tote Bag has been successfully created. We have processed your request for 1 unit, and it will be on its way to you shortly. If you have any further questions or need assistance, feel free to reach out. Best, Customer Support'
"""
user_prompt = f""" Here's the original message: {message}
def answer_product_inquiry(inquiry): prompt = f""" Your task is to answer a customer inquiry about one or multiple products.
You should: 1. Find the product(s) the customer refers to. This might be a specific product, or a general type of product.
For example, they might ask about a specific product id, or just a winter coat.
You can query the product catalog to find relevant information. It's up to you to understand what's the best strategy to find that product information.
Be careful: the customer might mention other products that do not relate to their inquiry.
Your job is to understand precisely the type of request they are making, and only query the database for the specific inquiry. If they mention a specific product id or type, but are not asking about those directly, you shouldn't look them up. Just look up information that will answer their inquiry.
2. Once you have the product information, write a response email to the customer.
Make the email tone professional, yet friendly. You should sound human so, if the customer mentions something in their email that's worth referring to, do it.
Do not add any other text, such as email subject or placeholders, just a clean email body.
Always sign as 'Customer Support'
Here's an example of the expected reply:
'Hi David,
Thank you for reaching out!
Both the LTH1098 Leather Backpack and the Leather Tote are great choices for work, but here are a few key differences: - Organization: The Backpack has more built-in compartments, including a padded laptop sleeve and multiple compartments, which make it ideal for organizing documents and electronics. - The Tote also offers a spacious interior and multiple pockets, but it’s slightly more open and less structured inside—great for quick access, but with fewer separate sections.
If your priority is organization and carrying a laptop securely, the LTH1098 Backpack would be the better fit.
Please let us know if there’s anything else we can assist you with, or if you'd like to place an order. Best, Customer Support'
Here's the user's inquiry: Subject: {inquiry["subject"]} Message: {inquiry["message"]}
Most query expansion methods either dig through feedback from initial search results or rely on pre-defined thesauruses. Query2doc skips both.
Instead, it uses LLMs to generate short, relevant pseudo-documents and appends them to your query — no retraining, no architecture changes.
How It Works
Use few-shot prompting (4 examples) to generate a passage based on a query.
Combine the original query and the LLM-generated text:
For BM25: repeat the query 5 times, then add the pseudo-doc.
For dense retrievers: simple [query] [SEP] [pseudo-doc].
Why It Matters
+15% nDCG@10 boost for BM25 on TREC DL.
Also improves dense models like DPR, SimLM, and E5 — even without fine-tuning.
Works best with bigger models — GPT-4 outperforms smaller ones.
Crucially, the combo of original query + pseudo-doc works better than either alone.
Limitations
Latency: >2 seconds per query — too slow for real-time.
Cost: ~550k LLM calls = ~$5K.
LLMs can hallucinate. Still need validation layers for production.
Takeaway
Query2doc is dead simple but surprisingly effective. It’s a plug-and-play upgrade for search systems — ideal for boosting retrieval quality when training data is scarce.
Just don’t expect real-time speed or perfect factual accuracy.
import chromadb
import openai
import os
# Set your OpenAI API key
openai.api_key = os.getenv("OPENAI_API_KEY")
# Step 1: Few-shot prompt template
def generate_pseudo_document(query):
prompt = f"""
Write a passage that answers the given query.
Query: what state is zip code 85282
Passage: 85282 is a ZIP code located in Tempe, Arizona. It covers parts of the Phoenix metro area and is known for being home to Arizona State University.
Query: when was pokemon green released
Passage: Pokémon Green was released in Japan on February 27, 1996, alongside Pokémon Red. These games were the first in the Pokémon series.
Query: {query}
Passage:"""
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt}],
max_tokens=150,
temperature=0.7,
)
return response.choices[0].message["content"].strip()
# Step 2: Initialize Chroma and add documents
client = chromadb.Client()
collection = client.create_collection("my_docs")
docs = [
"Pokémon Green was released in Japan in 1996.",
"Tempe, Arizona has ZIP code 85282.",
"Randy Newman sings the Monk theme song.",
"HRA is employer-funded; HSA is individually owned and tax-free."
]
collection.add(
documents=docs,
ids=[f"doc_{i}" for i in range(len(docs))]
)
# Step 3: Expand user query
user_query = "when was pokemon green released"
pseudo_doc = generate_pseudo_document(user_query)
expanded_query = f"{user_query} {pseudo_doc}"
# Step 4: Run ChromaDB search
results = collection.query(
query_texts=[expanded_query],
n_results=2
)
Retrieval-Augmented Generation (RAG) was supposed to fix everything. More accurate answers. Less hallucination. Instant access to domain-specific knowledge.
But in real-world deployments, the results often disappoint.
Answers feel off. Retrievals are irrelevant. Context seems lost. So what’s going wrong?
Let’s break down the core problems, and how to fix them.
1. Vector embeddings aren’t magic
RAG relies on vector embeddings to find semantically similar documents. But embeddings aren’t perfect.
They compress language into fixed-length vectors and, in that compression, nuance gets lost.
The issues:
Polysemy: One word, multiple meanings. Embeddings may pick the wrong sense.
Synonymy: Different words, same meaning — but often not close enough in vector space.
Dense mapping: Common terms dominate, drowning out contextually relevant ones.
Lossy compression: Some information simply disappears during vectorization.
Fragmented meaning: Chunking documents too finely can split up important context.
Bottom line: vector similarity ≠ true relevance.
2. Your query might be the problem
If your query is too vague, you’ll get shallow matches.
Too specific? You risk missing relevant documents that use slightly different phrasing.
Fix it with:
Query rephrasing: Reformulate user queries before embedding them, to better align with how data is structured.
Disambiguation: Make sure the model understands what you actually mean (replacing acronyms, etc.)
Context tuning: Keep queries focused and information-rich — not bloated or ambiguous.
Your retrieval is only as smart as your query.
3. Your chunking strategy is hurting you
Chunking is more than just splitting text. It’s a balancing act.
Too small, and you lose context. Too large, and you overload the model.
Strategies to explore:
Sliding window: Maintains continuity across chunks.
Recursive chunking: Uses document structure (headings, paragraphs) to guide splits.
Semantic chunking: Groups based on meaning, not just tokens.
Hybrid chunking: Combines multiple methods, customized per use case.
The right chunking strategy depends on your data and your goals.
4. You’re missing Named Entity Filtering (NEF)
Named Entity Recognition (NER) isn’t just for tagging people and places.
It can drastically sharpen your retrievals by filtering documents based on entity-level relevance.
Use it to:
Filter results to only include documents with relevant entities.
Refine embeddings by focusing on entity-rich sentences.
Reduce noise and boost relevance, especially for technical or domain-specific content.
Pair this with noun-phrase disambiguation, and you’ll see a big drop in hallucinations.
5. You’re using embeddings too early
Embeddings are great, but don’t make them do all the work upfront.
Sometimes, traditional keyword matching or metadata filtering gives a cleaner first pass. Use vector embeddings to rerank or refine after that.
Think hybrid:
Start with keyword or synonym-based retrieval.
Apply vector search as a second pass.
Fine-tune embeddings for your domain for even better alignment.
Precision + semantic recall = better results.
6. You’re not using advanced RAG techniques
RAG has evolved. Basic setups won’t cut it anymore.
Try these:
Reranking: Cross-encoders to reassess document relevance.
Query expansion: Add synonyms, related terms, or constraints.
Prompt compression: Strip irrelevant content before feeding it to the model.
Corrective RAG (CRAG): Evaluate and refine retrieved documents dynamically.
RAG Fusion: Generate multiple queries and fuse their results for broader coverage.
Contextual Metadata Filtering RAG (CMF-RAG): Automatically generate metadata filters from the user query.
Enrich documents with context: When chunking, add a summary of the page or document, for context.
Use what fits your data and needs. There’s no one-size-fits-all.
Putting it all together
How do you know what will work for your use case?
Set up automated tests:
Define a batch of 50–100 relevant questions
Use an LLM as evaluator
Iterate through different chunking strategies, hyperparameters, type of search, etc. and store results
Analyze results and choose the best setup
Final thoughts
RAG isn’t broke, it’s just misunderstood.
It’s easy to slap vector search on top of an LLM and call it a day.
But building a high-performance RAG system takes more.
Tune your queries.
Chunk your documents wisely.
Filter with entities.
Rerank with smarter models.
Layer retrieval techniques strategically.
In short: stop treating retrieval as an afterthought.
It’s half the battle.
And often the one you’re losing.
Feel free to reach out to me if you would like to discuss further, it would be a pleasure (honestly):
Google recently dropped a prompt engineering whitepaper packed with practical techniques for getting better results out of language models.
If you’ve ever felt like your AI responses were a little off, this cheat sheet might be what you need.
Prompting techniques
Start simple. For straightforward tasks, zero-shot prompting (no examples, just direct questions) often works wonders.
Need structure or style? One-shot or few-shot prompting guides your AI by providing clear examples to follow. This gives the model context without overwhelming it.
Want precision? System prompting clearly defines your expectations and output format, like JSON. No guesswork needed.
Looking to add personality? Role prompting assigns a voice or tone — “Act as a coach,” or “be playful.” It transforms generic outputs into engaging conversations.
Got a complex situation? Contextual prompting gives background and constraints. It steers the AI exactly where you need it to go.
Feeling stuck? Step-back prompting helps the AI take a broader view before narrowing down to specifics, improving clarity and creativity.
Facing intricate logic or math? Chain of Thought (CoT) prompts the AI to reason step-by-step, making complex tasks manageable.
Want accuracy? Use self-consistency — run multiple CoT iterations and select the most common answer. More tries, fewer errors.
Need diverse reasoning paths? Tree of Thoughts (ToT) explores multiple routes simultaneously, ideal for tough, open-ended problems.
Best practices
Always provide examples — this alone can drastically improve results.
Keep prompts simple, clear, and structured. Complexity is your enemy.
Specify your desired output explicitly, format and style included.
Because it’s fast, fun, and wildly creative. You go from idea to game in seconds. Great for prototyping, learning, or impressing your friends at brunch.
Imagine typing “a Flappy Bird clone” and watching it pop open in your browser — ready to play. No design. No dev work. Just vibes and velocity.
Don’t just eval. That’s dangerous. ast.literal_eval is safer and stricter.
Step 5 — Generate the game code using your prompt
def create_game_code(game_name: str) -> str: prompt = f””” You are a game developer. You are given a game name. Create code for that game in JavaScript, HTML, and CSS (all in one file). The game should be a simple game that can be played in the browser. It should be a single page game. Follow a json schema for the response: {{“game_code”: “game code”}} By default, use the html extension. “”” response = call_llm(prompt, game_name) return response[“game_code”]
Crafting the right system prompt
Talk to the LLM like it’s a dev on your team. Clear, structured, and friendly.
Step 6 — Save the generated game as HTML
def create_game_html(game_code: str): with open(“game.html”, “w”) as file: file.write(game_code)
Simple write-to-file. Now it exists on your machine.
Step 7 — Automatically open the game in the browser
I’ve been studying system design on my own and I feel that, as data scientists and AI engineers, we don’t see it enough.
At the beginning I was a bit lost, didn’t know many of the terms used in the domain.
I watched many Youtube tutorials, and most of them go into a level of detail that can be overwhelming if you’re not a software engineer.
Yet, many AI engineering jobs these days have a system design step in the recruiting process.
So, I thought it’d be a good idea to give an overview of what I’ve learned so far, focused on AI engineering.
This tutorial will be focused on system design interviews, but of course it can also help you learn system design in general, for your job.
I’ll be using a framework from the book “System Design Interview”, which suggests the following script for the interview:
Clarifying questions
Propose high level design and get buy-in
Deep dive
Wrap-up: refine the design
I’ve adapted this framework to make it more linked to AI Engineering, as well as more pragmatic, by outlining what I consider to be the minimum output required in each step.
And, for this tutorial, I took a question that I’ve seen in interviews for an AI Engineer position:
“Build a system that takes uploaded .csv files with different schemas and harmonizes them.”
So, let’s design!
Clarifying questions
In this first step, you should ask some general questions, to have a better view of the context of the problem, and some more specific ones, to define the precise perimeter you’re working on.
More specifically, you should end this step with at least this info:
context
functional features
non-functional features
key numbers
Context
Ask things like:
who will be using this?
how will they be using it?
where they will be using it (ex.: is it just one country, or worldwide)?
In our case, the system will be used in-company, to format multiple .csv files that come from different sources.
Their format and schema can always be different, so we need a robust and flexible solution that handles well this variability.
Those files will be uploaded by users, that don’t need the file right away: they just need it to be stored somewhere for later use by other systems.
It’s a small company, and they are all more or less in the same place.
Functional features
These are the things the product/service should be able to do.
In our example, there’s only one main functional feature: convert file.
But, we can also split that into 3 steps, which will help ups design our system later:
upload file
process file
store file
In a more complex app, like YouTube, functional features could be:
upload video
view video
search video
etc.
Make sure the interviewer is onboard with these. In a real-life situation, you’d have things like authentification, account creation, etc.
Non-functional features
These are things that your system should consider, like: scalability, availability, latency, etc.
In practice, there’s a few ones that you should almost always consider:
latency
availability vs. consistency
Latency means: what’s an acceptable time for the user to get a response?
The availability vs. consistency tradeoff refers to the idea that in a distributed system, you can’t always guarantee both that data is immediately consistent across all nodes and that it’s always available when requested — especially during network failures.
Example: Imagine a banking app where a user transfers money from their savings to their checking account. If the system prioritizes consistency, it might temporarily block access while syncing all servers to ensure the balance is accurate everywhere. If it prioritizes availability, it might show the new balance immediately — even if some servers haven’t updated yet — risking temporary inconsistencies.
In some services, availability is more important. In others, consistency is more important.
Don’t look at this at the system level, but at the level of each functional feature.
Our use case is very simple, with only one functional feature, and the choice between consistency and availability will depend on the type of data and how it’s used, so check with the interviewer.
For the latency, let’s assume anything under 1 minute is acceptable.
Key numbers
This will help you calculate the amount of data that goes through your system, as well as the storage needs.
In our use case, some important figures could be:
daily active users (ex.: 100)
files per user (ex.: 1)
average file size (ex.: 1 MB)
With these 3 numbers, you can already estimate the data volume:
daily: 100 x 1 x 1 MB = 0.1 GB
yearly: 0.1 GB x 365 = 36.5 GB
Those numbers will help us choose the best solutions for processing and storage.
For this example, let’s also assume there isn’t huge variance in the file size (there won’t be files over 10 MB).
Propose high-level design and get buy-in
With all this in hands, it’s time to start designing.
The minimal output here would be:
core entities
overall system design
address functional requirements
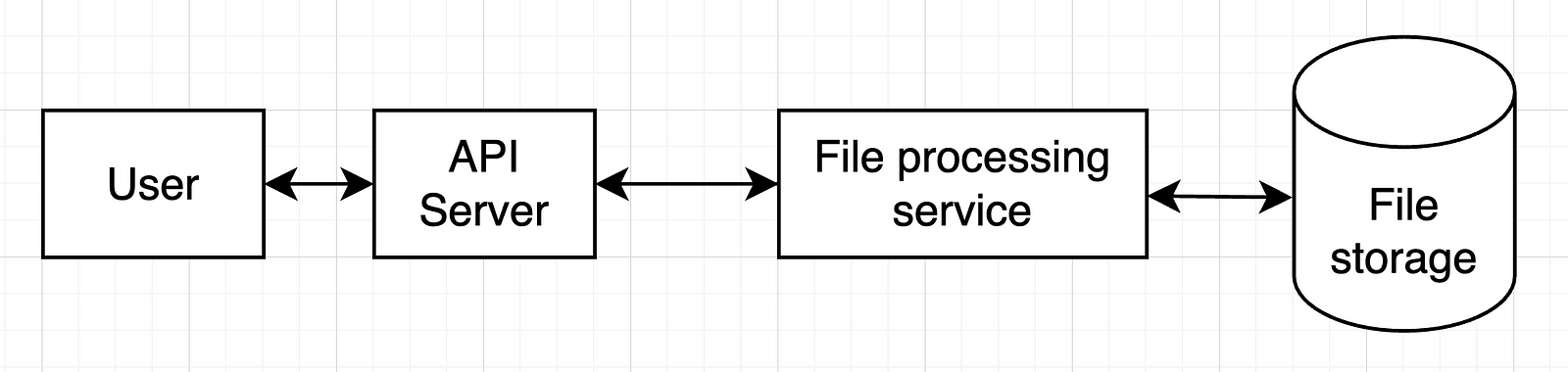
A single server design is a reasonable starting point for most use cases.
So, start with a user, a server, services and databases.
In our example, we can start with only one service, so the whole setup would look like this:
In a more complex system, we’d have more services and more databases.
Check with your interviewer if they’re OK with this and move on.
Deep dive
Now it’s time to detail the most important components of our previous design. That’s obviously the file processing service.
The minimal output:
address non-functional requirements
But it’s also good to have these (check with the interviewer what they are expecting):
API detail
data schema detail
tool choices
In our case, we should think in more detail on how those files would be processed.
My approach here (since we’re focused on AI solutions) is to use an LLM for this:
Give the LLM a “gold standard” format for our .csv files (column names and formats)
Give it a sample of the file to transform too (column names and formats)
Ask it for code that converts the file into the desired format
Run that code on the uploaded file
Store the resulting file
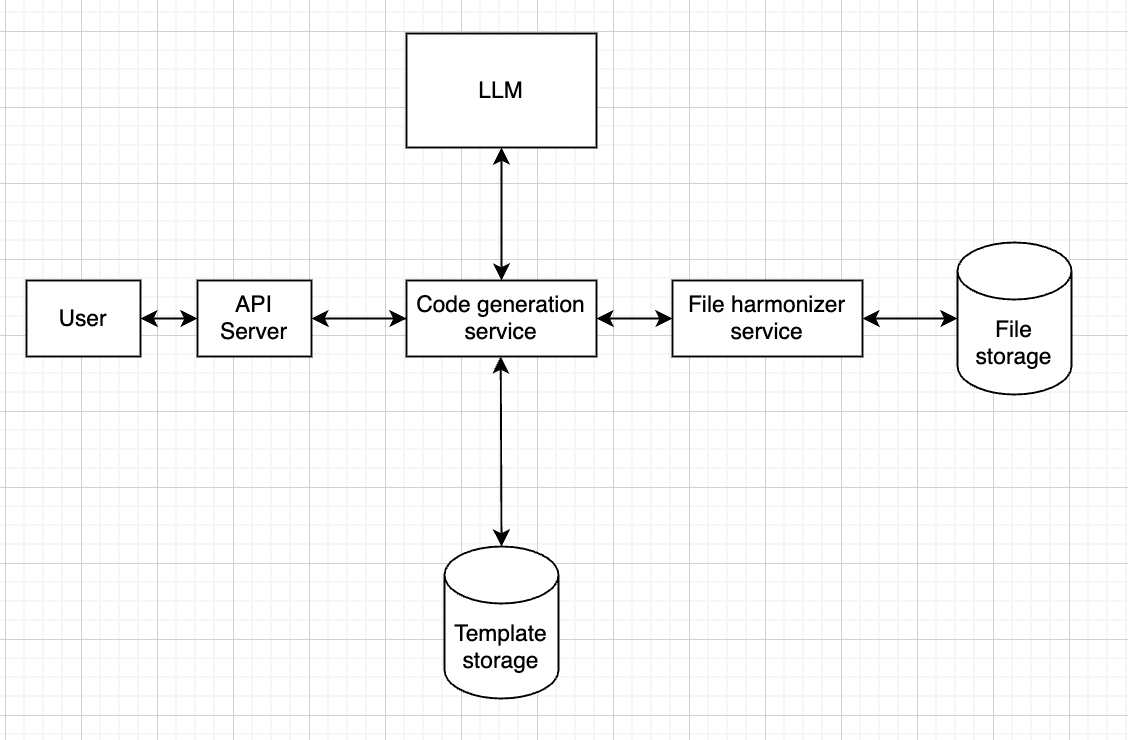
With this approach in mind, we can then look back into our design and what changes we should make to it:
We should probably separate code generation from code running, since these serve completely different purposes
There might be times when we get a file schema that we’ve seen already. In that case, we can have some sort of storage that allows us to cache code used before.
This would result in something like this:
Meaning that the code generation service will first check in “template storage” if we have seen this format before.
If so, it will fetch the code from that storage and send it to the file harmonizer service.
If not, then it will call the LLM.
Now, one of the non-functional requirements was a latency under 1 minute.
Given the average file sizes, it’s reasonable to assume the whole thing will take less than 1 minute to run.
In terms of technical choices, a few things are relevant here:
the type of model
the type of storage
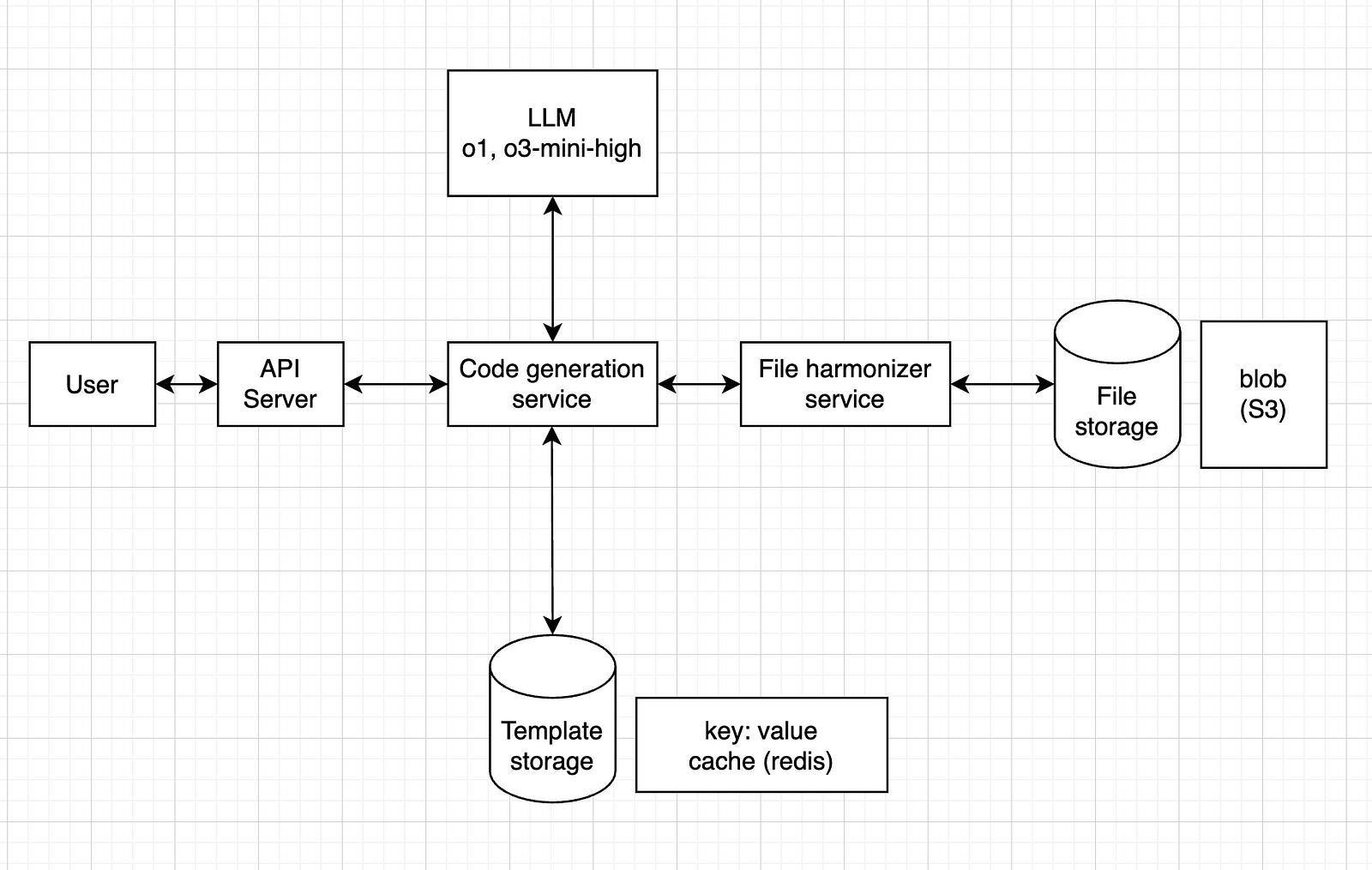
For the model, any model should do it, but I think it’s safer to go for a reasoning model, such as o1 or o3-mini-high.
For the file storage, since it’s just .csv files, a blob storage service like Amazon S3 should work.
For the template storage, we could have a key: value system, where the key is the schema (or a hash version of it) and the value is the corresponding code (or maybe a path to a blob storage with the .py file). One tool that can do this is Redis.
So, our final design would look like this:
Wrap up
In this step, we can refine our design, or at least find improvement opportunities.
Essentially, show what could be improved if you had more time.
In our case, here are some examples:
a first iteration loop: what happens if the code fails to run? How do we call the LLM again, with the error message, to ask for new code?
a fallback system: if the code fails n times in a row, how can we make sure it stops trying, and gives some error message to the user, instead of running an infinite loop?
backup: how can we make sure our file storage has some sort of backup?
simultaneous requests: how can we handle cases where multiple users upload at the same time? Should we use a message queue system?
The idea is to find bottlenecks, single points of failure and things like that, to improve on.
Conclusion and additional resources
I’ve seen many resources on system design interviews, and most of them are focused on software engineers, with very complex systems, addressing things that are usually not handled by AI engineers.
Yet, when the interview is for an AI engineer role, the request can often be more like this one: instead of multiple services and use cases, a sort of linear processing system, focused on LLMs, etc.
I’ve read two books on the topic:
“System Design Interview” is more generic, and I found it more useful, giving an overview of how to approach these interviews.
“Generative AI System Design Interview” is more focused on building things from scratch (LLMs, image generation models, etc.), which is not as common as using external APIs.
If you’re more into courses, I can recommend these two:
Traditional language models (LLMs) process text one word at a time.
They predict the next token based on the ones before it.
That works well, but it’s not how humans think.
When we write or speak, we don’t just string words together.
We organize our thoughts into sentences, ideas, and concepts.
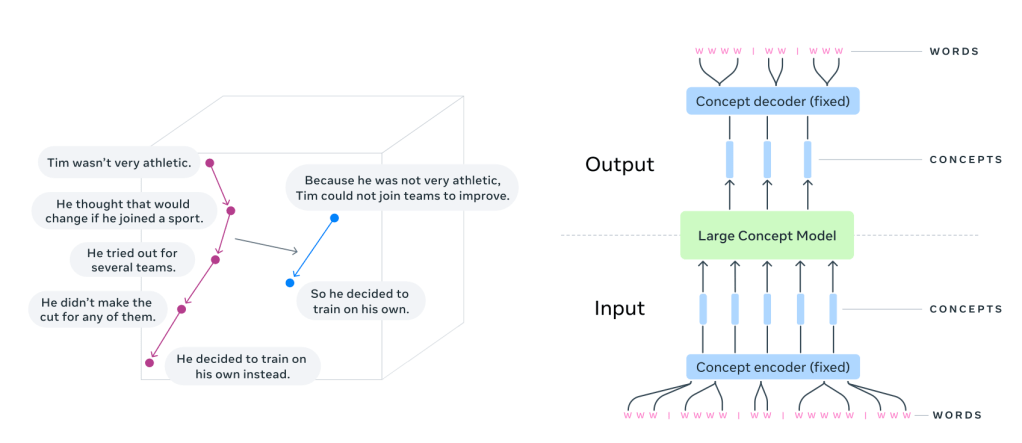
That’s where Large Concept Models (LCMs) come in.
Instead of predicting the next word, LCMs predict the next sentence.
Each sentence is treated as a concept — a standalone unit of meaning.
That’s a big shift.
Why does this matter?
LLMs operate at the token level, making them great at text generation but limited in their ability to reason hierarchically. They tend to get lost in long-form content, struggle with consistency, and often fail to keep track of structured ideas.
LCMs take a different approach. They generate text in sentence embeddings, operating in a high-dimensional space (like SONAR) instead of token sequences. Instead of focusing on words, they predict thoughts in a way that’s language- and modality-agnostic.
This has big implications:
Better context understanding — By modeling entire sentences as units, LCMs improve coherence and logical flow.
Multilingual and multimodal — Trained on 200+ languages, LCMs can generalize across text and speech without additional fine-tuning.
More efficient generation — Since they work at a higher level, they process fewer steps, making them faster and more scalable than token-based models.
Stronger zero-shot performance — LCMs outperform LLMs of the same size in summarization and text expansion tasks, even in languages they weren’t explicitly trained on.
The technical shift
LLMs generate text autoregressively, predicting one token at a time. This requires them to process long token sequences and maintain coherence through implicit context modeling.
LCMs, on the other hand, predict the next sentence embedding in a latent space.
Instead of raw tokens, they work with sentence representations from SONAR, a multilingual embedding model.
SONAR is trained to encode and decode sentences across 200+ languages into and out of a single shared representation space. When an LCM needs to handle a new language or modality, only the SONAR encoder/decoder must be updated — leaving the central model untouched.
The embeddings are processed autoregressively using diffusion models, MSE regression, or quantized representations — allowing LCMs to generalize across languages and modalities without needing explicit tokenization.
This shift reduces computational complexity, makes it easier to edit long-form text, and allows AI to reason at a higher level of abstraction.
The results
When tested on summarization and summary expansion, LCMs outperformed traditional LLMs of the same size.
They showed strong generalization across multiple languages — without additional fine-tuning.
They handled long-form text more coherently than token-based models.
And because they work in a modular embedding space, they can be extended to new languages, speech, or even sign language, without retraining the entire model.
Challenges
Sentence splitting
LCMs rely on robust sentence segmentation. Very long or tricky “sentences” can hurt performance.
Out-of-distribution embeddings
With MSE or diffusion, the model could predict vectors that don’t perfectly map back to valid text. Diffusion or well-tuned quantization helps mitigate this.
Averaging vs. sampling
A purely MSE-based approach might average all potential continuations into a single “blurry” embedding. Diffusion or discrete codebooks allow multiple plausible completions.
The Future of Language Modeling?
LLMs work. But they are word-by-word prediction machines.
LCMs take a different path — one that focuses on thoughts, not just tokens.
By modeling language at the concept level, they bring AI closer to how humans structure ideas.
This isn’t just an optimization. It’s a fundamental shift in how AI understands and generates language.
And it might just change how we build the next generation of intelligent systems.
Chatbots are becoming more powerful and accessible than ever. In this tutorial, you’ll learn how to build a simple chatbot using Streamlit and OpenAI’s API in just a few minutes.
Prerequisites
Before we start coding, make sure you have the following:
Python installed on your computer
A code editor (I recommend Cursor, but you can use VS Code, PyCharm, etc.)
An OpenAI API key (we’ll generate one shortly)
A GitHub account (for deployment)
Step 1: Setting Up the Project
We’ll use Poetry for dependency management. It simplifies package installation and versioning.
Initialize the Project
Open your terminal and run:
# Initialize a new Poetry project
poetry init
# Create a virtual environment and activate it
poetry shell
Install Dependencies
Next, install the required packages:
poetry add streamlit openai
Set Up OpenAI API Key
Go to OpenAI and get your API key. Then, create a .streamlit/secrets.toml file and add:
OPENAI_API_KEY="your-openai-api-key"
Make sure to never expose this key in public repositories!
Step 2: Creating the Chat Interface
Now, let’s build our chatbot’s UI. Create a new folder: streamlit-chatbot, and add a file to it, called app.py with the following code:
import streamlit as st
from openai import OpenAI
# Access the API key from Streamlit secrets
api_key = st.secrets["OPENAI_API_KEY"]
client = OpenAI(api_key=api_key)
st.title("Simple Chatbot")
# Initialize chat history
if "messages" not in st.session_state:
st.session_state.messages = []
# Display previous chat messages
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# Chat input
if prompt := st.chat_input("What's on your mind?"):
st.session_state.messages.append(
{"role": "user", "content": prompt}
)
with st.chat_message("user"):
st.markdown(prompt)
This creates a simple UI where:
The chatbot maintains a conversation history.
Users can type their messages into an input field.
Messages are displayed dynamically.
Step 3: Integrating OpenAI API
Now, let’s add the AI response logic:
# Get assistant response
with st.chat_message("assistant"):
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": m["role"],
"content": m["content"]} for m in st.session_state.messages
])
assistant_response = response.choices[0].message.content
st.markdown(assistant_response)
# Add assistant response to chat history
st.session_state.messages.append({"role": "assistant", "content": assistant_response})
This code:
Sends the conversation history to OpenAI’s GPT-3.5-Turbo model.
Retrieves and displays the assistant’s response.
Saves the response in the chat history.
Step 4: Deploying the Chatbot
Let’s make our chatbot accessible online by deploying it to Streamlit Cloud.
Initialize Git and Push to GitHub
Run these commands in your project folder:
git init
git add .
git commit -m "Initial commit"
Create a new repository on GitHub and do not initialize it with a README. Then, push your code:
Machine learning models typically predict outcomes based on what they’ve seen — but what about what they haven’t?
Google tackled this issue by integrating causal reasoning into its ML training, optimizing when to show Google Drive results in Gmail search.
The result?
A 9.15% increase in click-through rates without costly A/B tests.
Let’s break it down.
The problem: biased observational data
Traditional ML models train on historical user behavior, assuming that past actions predict future outcomes.
But this approach is inherently biased because it only accounts for what actually happened — not what could have happened under different conditions.
Example: Gmail sometimes displays Google Drive results in search. If a user clicks, does that mean they needed the result? If they don’t click, would they have clicked if Drive results were presented differently?
Standard ML models can’t answer these counterfactual questions.
Google’s approach: Causal ML in action
Instead of treating all users the same, Google’s model categorized them into four response types based on their likelihood to click:
Compliers — Click only if Drive results are shown.
Always-Takers — Click regardless of whether results are shown.
Never-Takers — Never click Drive results.
Defiers — Click only if Drive results are not shown (a rare edge case).
The challenge? You can’t directly observe these categories — a user only experiences one version of reality.
Google solved this by estimating counterfactual probabilities, essentially asking: How likely is a user to click if the result were shown, given that it wasn’t?
The key insight: optimizing for the right users
Instead of optimizing blindly for clicks, the model focused on:
Prioritizing Compliers (since they benefit the most from Drive results).
Accounting for Always-Takers (who don’t need Drive suggestions to click).
This logic was embedded into the training objective function, ensuring that the model learned from causal relationships rather than just surface-level patterns.
The Results: Smarter Personalization Without Experiments
By integrating causal logic into ML training, Google achieved:
+9.15% increase in click-through rate (CTR)
Only +1.4% increase in resource usage (not statistically significant)
No need for costly A/B testing
This proves that causal modeling can reduce bias in implicit feedback, making machine learning models more adaptive, efficient, and user-friendly — all without disrupting the user experience.
Why This Matters
Most companies rely on A/B testing to optimize product features, but sometimes that approach can be expensive, or just not possible at all.
Causal ML offers a way to refine decisions without running thousands of real-world experiments.
Google’s work shows that the future of ML isn’t just about better predictions — it’s about understanding why users behave the way they do and making decisions accordingly.