Traditional language models (LLMs) process text one word at a time.
They predict the next token based on the ones before it.
That works well, but it’s not how humans think.
When we write or speak, we don’t just string words together.
We organize our thoughts into sentences, ideas, and concepts.
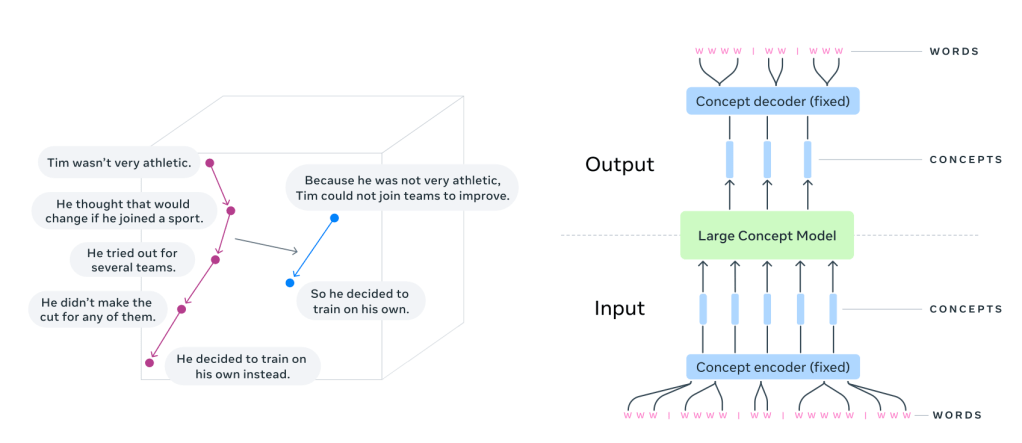
That’s where Large Concept Models (LCMs) come in.
Instead of predicting the next word, LCMs predict the next sentence.
Each sentence is treated as a concept — a standalone unit of meaning.
That’s a big shift.
Why does this matter?
LLMs operate at the token level, making them great at text generation but limited in their ability to reason hierarchically. They tend to get lost in long-form content, struggle with consistency, and often fail to keep track of structured ideas.
LCMs take a different approach. They generate text in sentence embeddings, operating in a high-dimensional space (like SONAR) instead of token sequences. Instead of focusing on words, they predict thoughts in a way that’s language- and modality-agnostic.
This has big implications:
Better context understanding — By modeling entire sentences as units, LCMs improve coherence and logical flow.
Multilingual and multimodal — Trained on 200+ languages, LCMs can generalize across text and speech without additional fine-tuning.
More efficient generation — Since they work at a higher level, they process fewer steps, making them faster and more scalable than token-based models.
Stronger zero-shot performance — LCMs outperform LLMs of the same size in summarization and text expansion tasks, even in languages they weren’t explicitly trained on.
The technical shift
LLMs generate text autoregressively, predicting one token at a time. This requires them to process long token sequences and maintain coherence through implicit context modeling.
LCMs, on the other hand, predict the next sentence embedding in a latent space.
Instead of raw tokens, they work with sentence representations from SONAR, a multilingual embedding model.
SONAR is trained to encode and decode sentences across 200+ languages into and out of a single shared representation space. When an LCM needs to handle a new language or modality, only the SONAR encoder/decoder must be updated — leaving the central model untouched.
The embeddings are processed autoregressively using diffusion models, MSE regression, or quantized representations — allowing LCMs to generalize across languages and modalities without needing explicit tokenization.
This shift reduces computational complexity, makes it easier to edit long-form text, and allows AI to reason at a higher level of abstraction.
The results
When tested on summarization and summary expansion, LCMs outperformed traditional LLMs of the same size.
They showed strong generalization across multiple languages — without additional fine-tuning.
They handled long-form text more coherently than token-based models.
And because they work in a modular embedding space, they can be extended to new languages, speech, or even sign language, without retraining the entire model.
Challenges
Sentence splitting
LCMs rely on robust sentence segmentation. Very long or tricky “sentences” can hurt performance.
Out-of-distribution embeddings
With MSE or diffusion, the model could predict vectors that don’t perfectly map back to valid text. Diffusion or well-tuned quantization helps mitigate this.
Averaging vs. sampling
A purely MSE-based approach might average all potential continuations into a single “blurry” embedding. Diffusion or discrete codebooks allow multiple plausible completions.
The Future of Language Modeling?
LLMs work. But they are word-by-word prediction machines.
LCMs take a different path — one that focuses on thoughts, not just tokens.
By modeling language at the concept level, they bring AI closer to how humans structure ideas.
This isn’t just an optimization. It’s a fundamental shift in how AI understands and generates language.
And it might just change how we build the next generation of intelligent systems.
Chatbots are becoming more powerful and accessible than ever. In this tutorial, you’ll learn how to build a simple chatbot using Streamlit and OpenAI’s API in just a few minutes.
Prerequisites
Before we start coding, make sure you have the following:
Python installed on your computer
A code editor (I recommend Cursor, but you can use VS Code, PyCharm, etc.)
An OpenAI API key (we’ll generate one shortly)
A GitHub account (for deployment)
Step 1: Setting Up the Project
We’ll use Poetry for dependency management. It simplifies package installation and versioning.
Initialize the Project
Open your terminal and run:
# Initialize a new Poetry project
poetry init
# Create a virtual environment and activate it
poetry shell
Install Dependencies
Next, install the required packages:
poetry add streamlit openai
Set Up OpenAI API Key
Go to OpenAI and get your API key. Then, create a .streamlit/secrets.toml file and add:
OPENAI_API_KEY="your-openai-api-key"
Make sure to never expose this key in public repositories!
Step 2: Creating the Chat Interface
Now, let’s build our chatbot’s UI. Create a new folder: streamlit-chatbot, and add a file to it, called app.py with the following code:
import streamlit as st
from openai import OpenAI
# Access the API key from Streamlit secrets
api_key = st.secrets["OPENAI_API_KEY"]
client = OpenAI(api_key=api_key)
st.title("Simple Chatbot")
# Initialize chat history
if "messages" not in st.session_state:
st.session_state.messages = []
# Display previous chat messages
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# Chat input
if prompt := st.chat_input("What's on your mind?"):
st.session_state.messages.append(
{"role": "user", "content": prompt}
)
with st.chat_message("user"):
st.markdown(prompt)
This creates a simple UI where:
The chatbot maintains a conversation history.
Users can type their messages into an input field.
Messages are displayed dynamically.
Step 3: Integrating OpenAI API
Now, let’s add the AI response logic:
# Get assistant response
with st.chat_message("assistant"):
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": m["role"],
"content": m["content"]} for m in st.session_state.messages
])
assistant_response = response.choices[0].message.content
st.markdown(assistant_response)
# Add assistant response to chat history
st.session_state.messages.append({"role": "assistant", "content": assistant_response})
This code:
Sends the conversation history to OpenAI’s GPT-3.5-Turbo model.
Retrieves and displays the assistant’s response.
Saves the response in the chat history.
Step 4: Deploying the Chatbot
Let’s make our chatbot accessible online by deploying it to Streamlit Cloud.
Initialize Git and Push to GitHub
Run these commands in your project folder:
git init
git add .
git commit -m "Initial commit"
Create a new repository on GitHub and do not initialize it with a README. Then, push your code:
Machine learning models typically predict outcomes based on what they’ve seen — but what about what they haven’t?
Google tackled this issue by integrating causal reasoning into its ML training, optimizing when to show Google Drive results in Gmail search.
The result?
A 9.15% increase in click-through rates without costly A/B tests.
Let’s break it down.
The problem: biased observational data
Traditional ML models train on historical user behavior, assuming that past actions predict future outcomes.
But this approach is inherently biased because it only accounts for what actually happened — not what could have happened under different conditions.
Example: Gmail sometimes displays Google Drive results in search. If a user clicks, does that mean they needed the result? If they don’t click, would they have clicked if Drive results were presented differently?
Standard ML models can’t answer these counterfactual questions.
Google’s approach: Causal ML in action
Instead of treating all users the same, Google’s model categorized them into four response types based on their likelihood to click:
Compliers — Click only if Drive results are shown.
Always-Takers — Click regardless of whether results are shown.
Never-Takers — Never click Drive results.
Defiers — Click only if Drive results are not shown (a rare edge case).
The challenge? You can’t directly observe these categories — a user only experiences one version of reality.
Google solved this by estimating counterfactual probabilities, essentially asking: How likely is a user to click if the result were shown, given that it wasn’t?
The key insight: optimizing for the right users
Instead of optimizing blindly for clicks, the model focused on:
Prioritizing Compliers (since they benefit the most from Drive results).
Accounting for Always-Takers (who don’t need Drive suggestions to click).
This logic was embedded into the training objective function, ensuring that the model learned from causal relationships rather than just surface-level patterns.
The Results: Smarter Personalization Without Experiments
By integrating causal logic into ML training, Google achieved:
+9.15% increase in click-through rate (CTR)
Only +1.4% increase in resource usage (not statistically significant)
No need for costly A/B testing
This proves that causal modeling can reduce bias in implicit feedback, making machine learning models more adaptive, efficient, and user-friendly — all without disrupting the user experience.
Why This Matters
Most companies rely on A/B testing to optimize product features, but sometimes that approach can be expensive, or just not possible at all.
Causal ML offers a way to refine decisions without running thousands of real-world experiments.
Google’s work shows that the future of ML isn’t just about better predictions — it’s about understanding why users behave the way they do and making decisions accordingly.
A quantitative exploration of the relationship between technology, labor and wealth
I see many people say AI will take our jobs any time now, based on the following narrative: the better AI becomes, the less companies will need us, therefore we will be replaced.
It’s an interesting chain of thought, but does it have the empirical basis to back it up? In other words, does reality match the story? Well, it doesn’t seem so.
It’s common to engage in this sort of discussion with well-thought arguments, based purely on conjectures, without looking at the existing body of scientific work nor at the data. I propose we take a tour of those two dimensions, to see if we can learn a thing or two from the empirical evidence.
Before we start, there is one link we need to establish: technology increases productivity. Here, we are talking from an economics perspective. Don’t think “when I have my cellphone I can’t work as much”. Here we are looking more at “the more technology in the world, the more we can produce with the same amount of work”.
This phenomenon is explained by the ability of technology to automate tasks, streamline processes, and facilitate the creation of new products and services. The intrinsic connection between technology and productivity is fundamental to understanding everything else you will read here.
With that out of the way, let’s see what science and data have to say about the impact of AI on our jobs.
Scientific work
Will AI take our jobs? This question can be seen as a specific case of the broader, more strucured question “does technology increase unemployment?”.
Unsurprisingly, this question has been asked by researchers many times before: a meta-analysis from 2022 that looked at 127 studies concluded that there is more evidence suggesting that technology creates net jobs than the other way around [1]. Their analysis specifically focuses on industrialized economies, to capture technological change at the frontier. They have also explored how this effect can be different depending on how we look at technology, but we will talk more about this later.
Some of the fear of AI comes from the narrative that, since AI makes us more productive, companies will need less of us to do the same job and, therefore, they will hire less of us. So, another study, from the European Central Bank [2], looked at the more general question “does productivity growth threaten employment?”. It turns out the answer is no. Even though some industries with higher productivity have seen fewer jobs, overall, the growth in productivity hasn’t really harmed employment. The study shows that one industry becoming more productive doesn’t automatically mean it will hire more people. However, it suggests that the positive impacts of productivity in one area can still create more jobs in other parts of the economy, offsetting any job losses in sectors with productivity gains. So, in the big picture, productivity growth has actually led to more jobs across various sectors. This study also concluded that current technology advances might bring a positive contribution to net jobs:
[…] the source of productivity growth matters for its aggregate employment consequences. Given that service sector productivity growth appears to have relatively strong employment spillovers, our findings suggest that the productivity growth spurred by the spread of (ultimately) general-purpose technologies such as robotics from heavy industry and into services may prove a boon for employment growth.
Anothery interesting study, from the OECD [3], spanning 13 countries over two decades, investigates the relationship between productivity, employment, and wages. It found a positive correlation between productivity growth and increased employment and wages, both at the firm and aggregate levels:
At the more aggregate level, the role of reallocation and links across industries becomes more evident. Yet also here, results confirm that productivity growth is, overall, associated with positive changes in employment and wages. Increasing employment among expanding firms tends to outweigh decreasing employment in shrinking or exiting firms. Furthermore, productivity gains at the industry level contribute to stronger employment growth in downstream industries through value chains.
Looking at AI more specifically, a panel study from 2023 shows evidence that it decreases the level of unemployment, at least in high-tech developed countries [4]. The study investigated how AI affects unemployment in 24 high-tech developed countries from 2005 to 2021, using Google Trend Index data related to AI and unemployment rates.
Data
Now, for some extra context, let’s take the time to explore some of the data ourselves, to answer some broeader questions. If technology is evolving (and I don’t think anyone questions that), and this is not decreasing the number of jobs available, then what is it doing for us?
We are not necessarily “less employed”
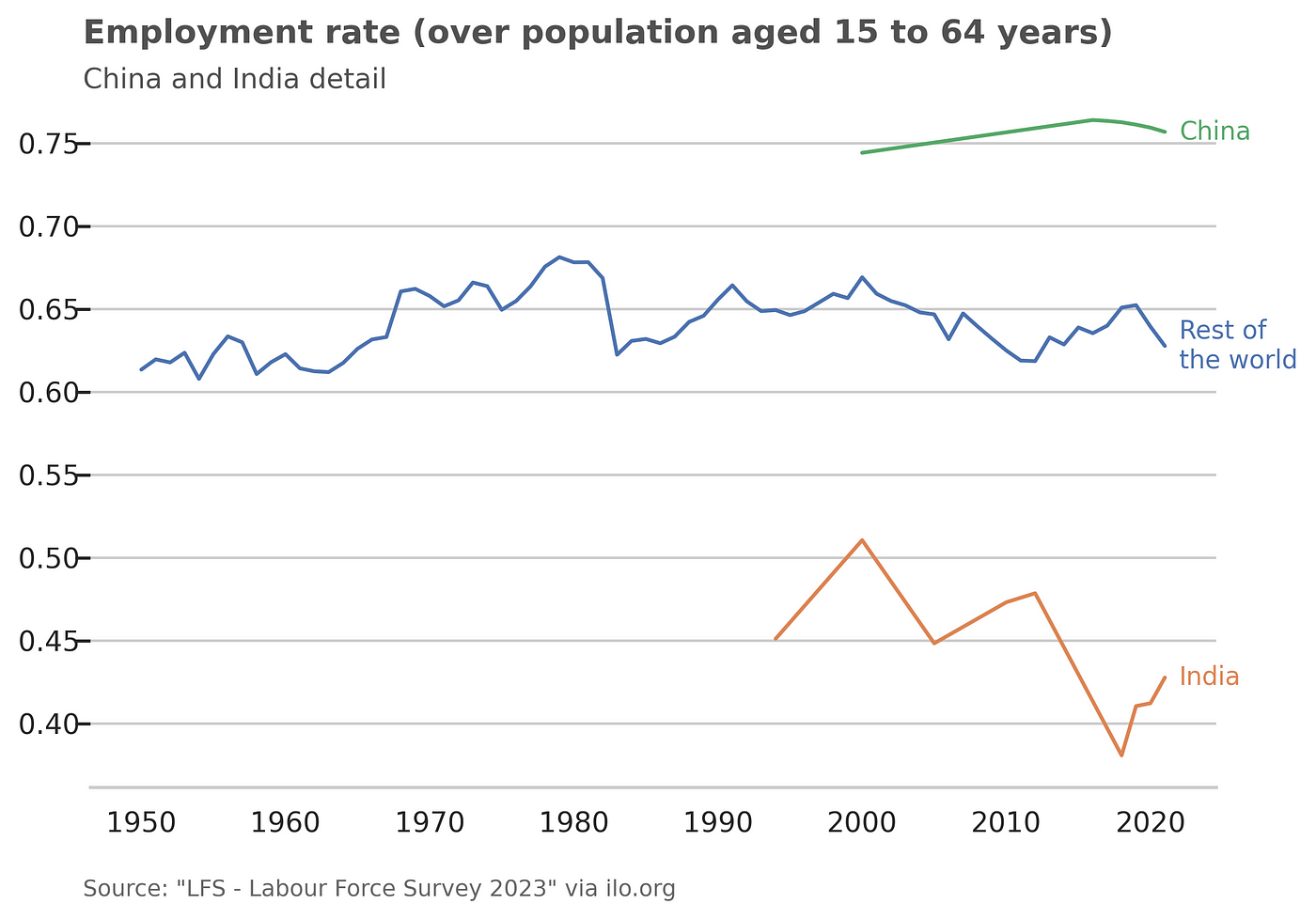
To contribute to the body of evidence that we are not being replaced by technology, let us look at the employment rates in the world since 1950:
Image by author
I put China and India separately because their data was not available for every year and, given their populations, this had a big impact on the variability of the indicator, specially since the 1990s.
We can see that, despite the impressive technological advances over the last 70 years, employment rates do not seem to be a bigger issue now than they were back then.
We are working less
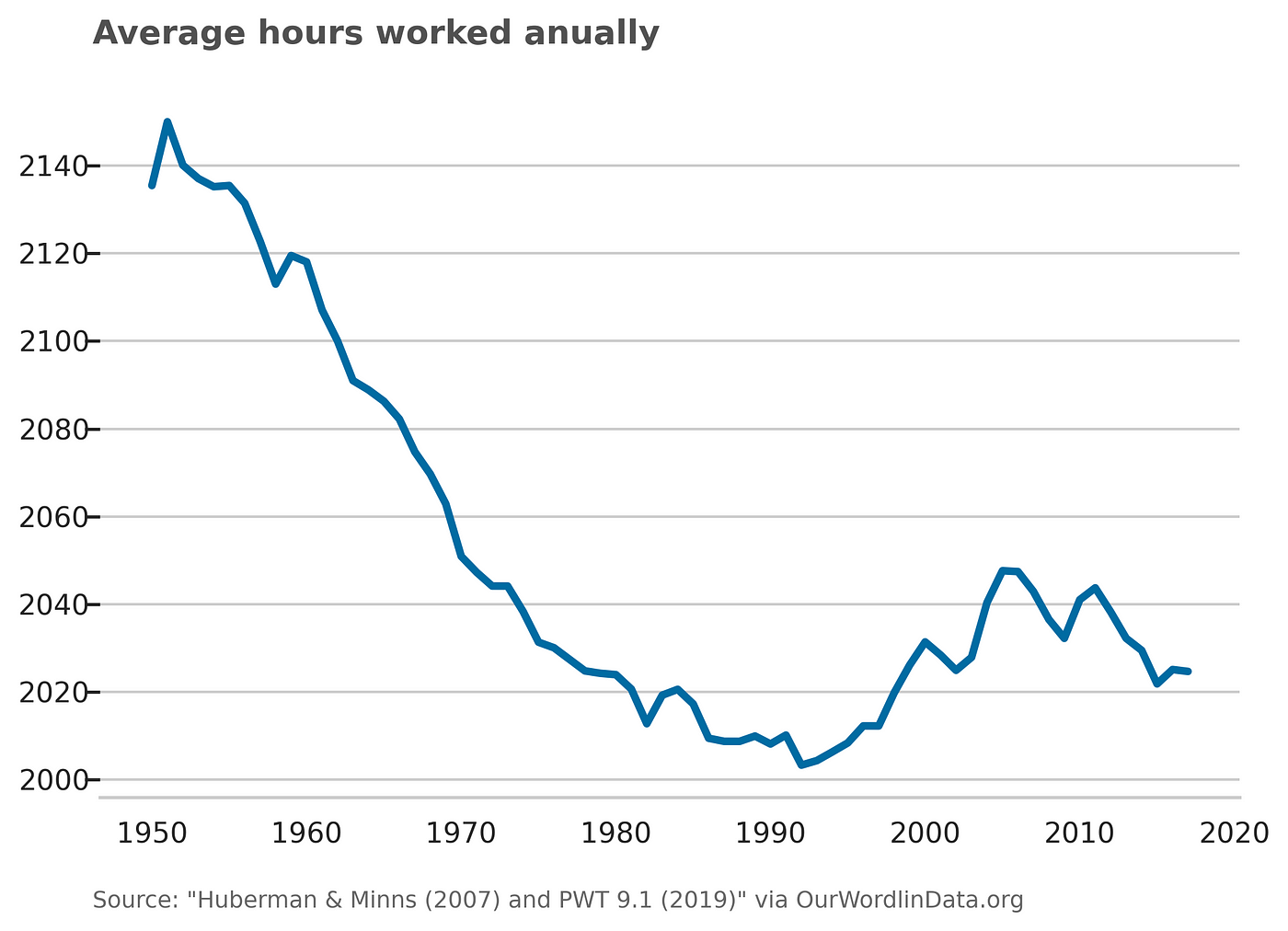
We are, on the other hand, working much less than our ancestors:
Image by author
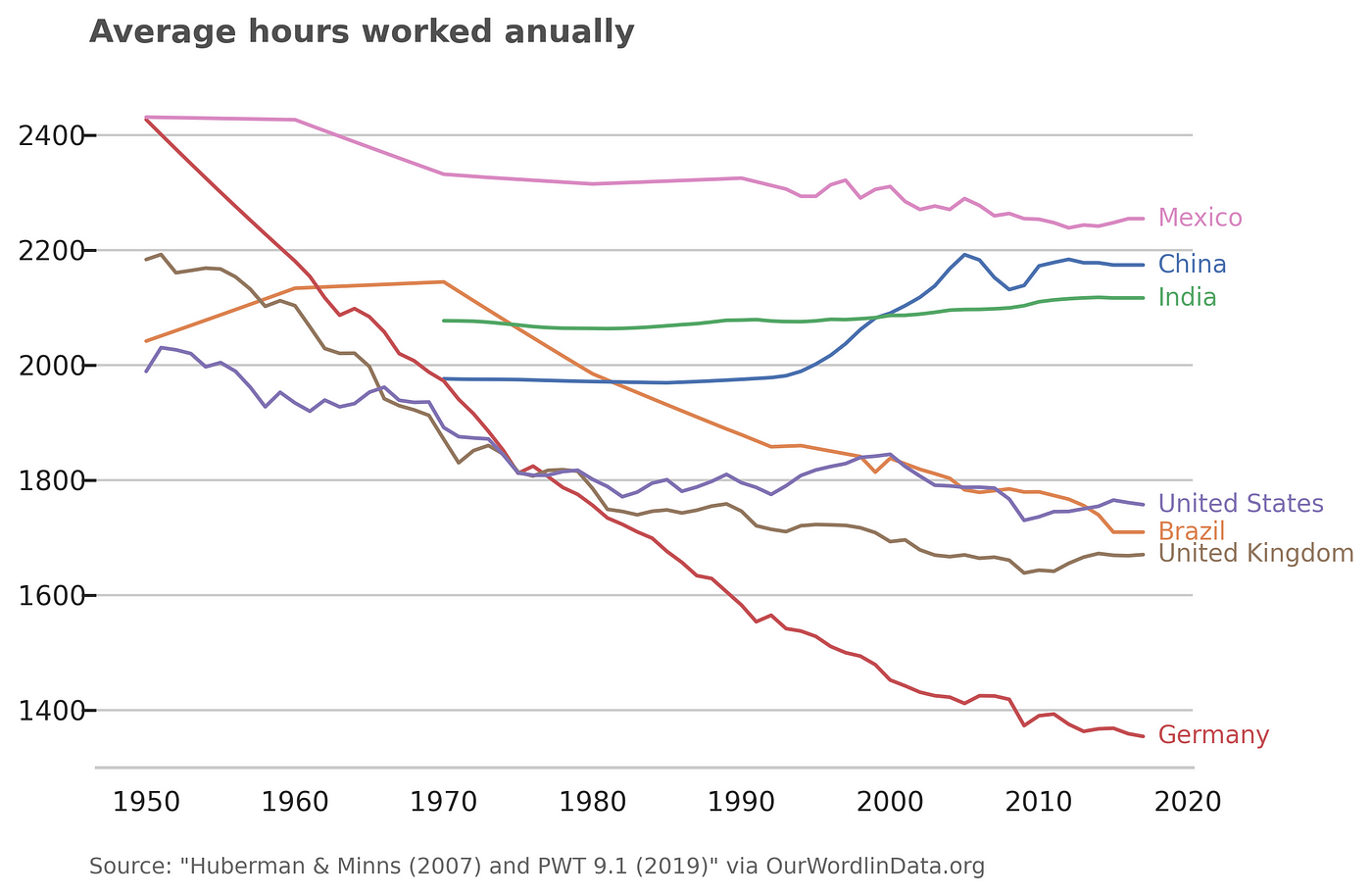
This global trend, however, is not the same everywhere:
Image by author
Richer countries are reducing their working hours at higher rate than the rest. I cherry-picked some specific countries that are representative of different trends:
Germany is an example of a rich country where people worked much more than the rest of the world, and has drastically decreased since then;
The US has become substantially richer since the 1950’s, yet its work load have not decreased significantly;
China and India seem to be going in the opposite direction of the rest of the world, working longer hours.
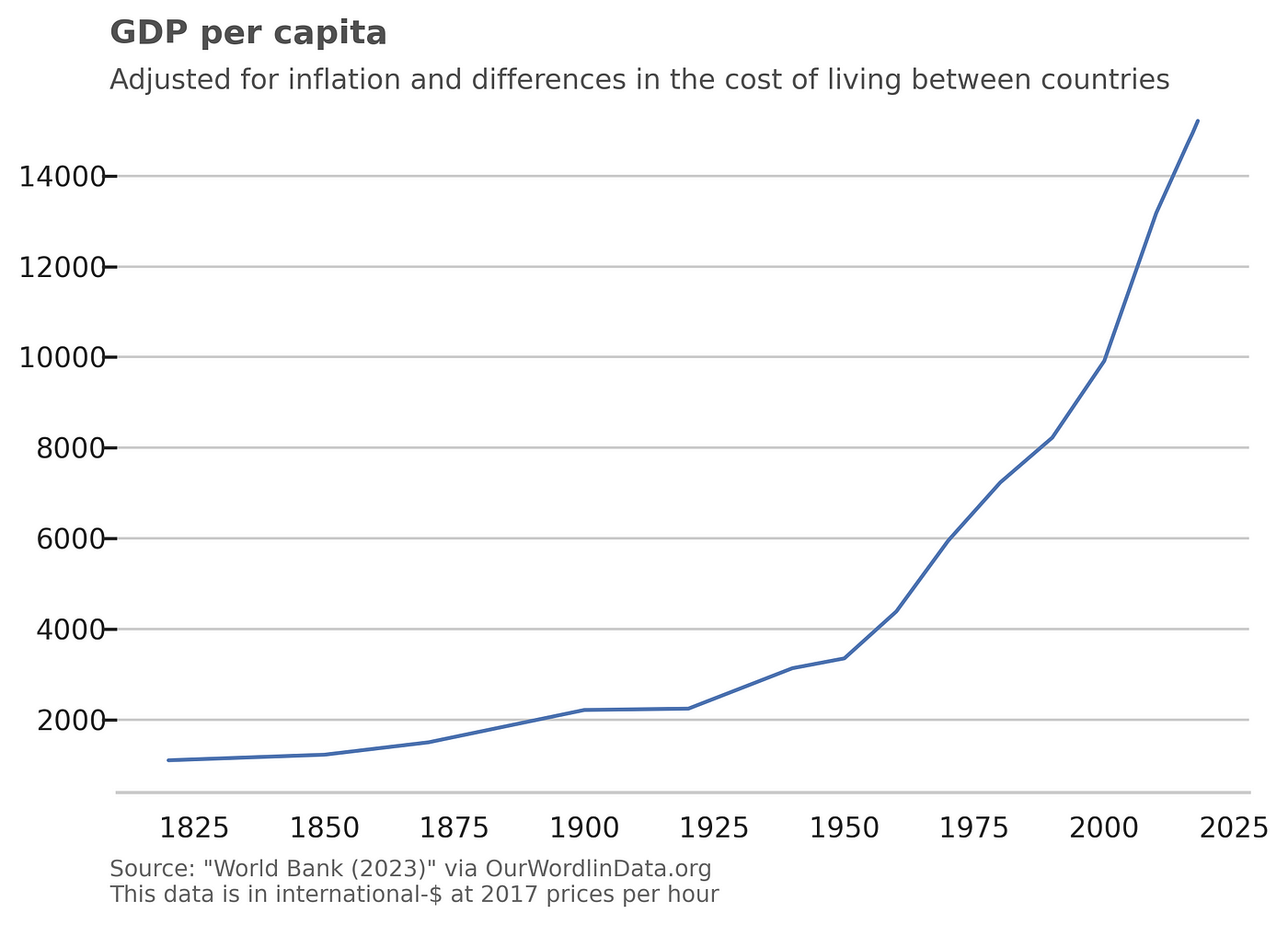
We are richer than ever
I hope this does not come as a surprise, but we have never been richer:
Image by author
So, even though the world is working less, pretty much every country got richer.
Of course, the distribution of that wealth was not the same across the globe. Pretty much every country got richer, but some got richer than others (again, no surprise):
Image by author
But how can we work less and make more money? What allowed that to happen? Well, we happen to have become more productive over time thanks, in part, to technology.
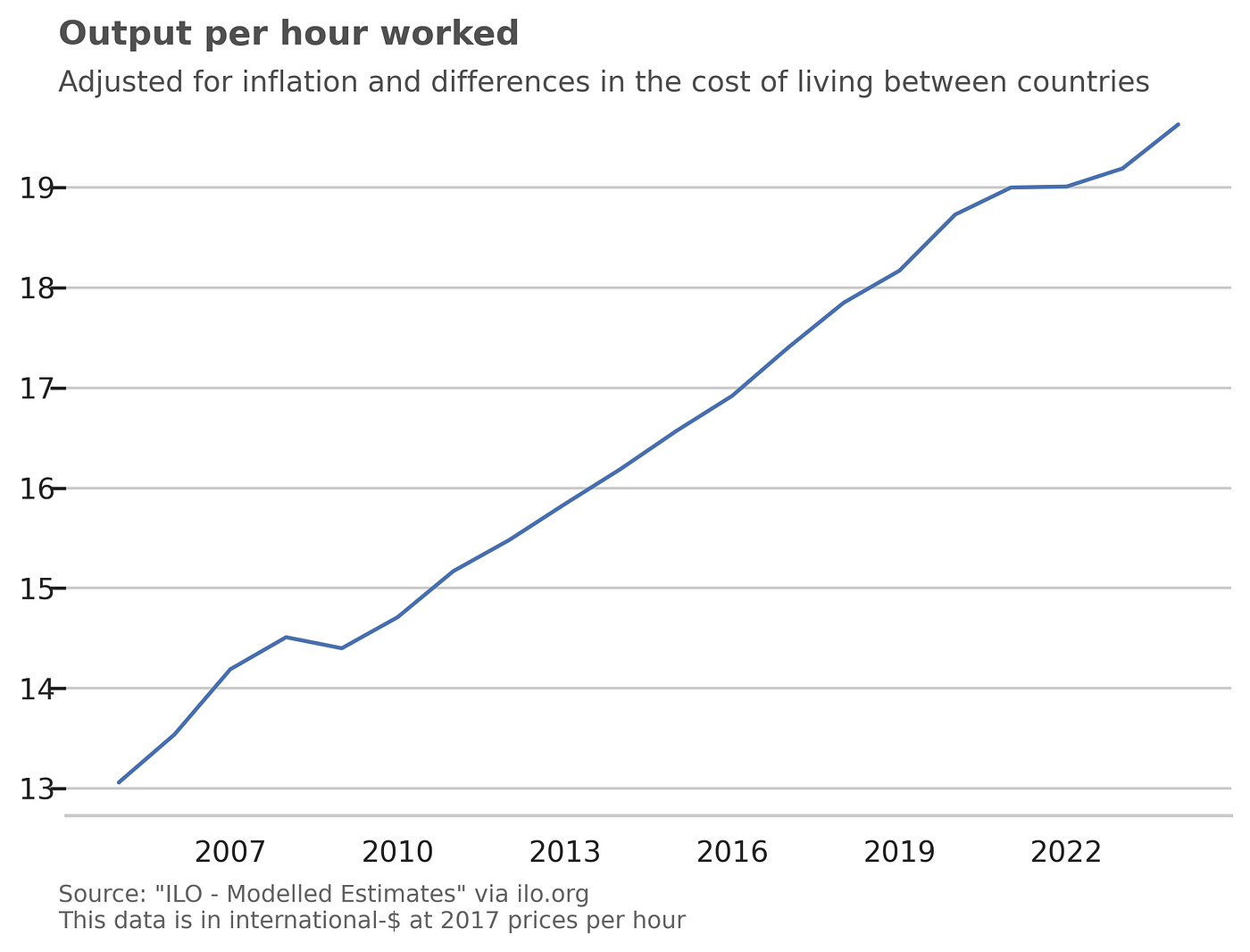
We are more productive
Technology, education and solid institutions contribute to productivity, and we can see the results over the years:
Image by author
Unfortunately, I couldn’t find data older from before the 2000s but, given the decrease in number of hours worked and the increase in GDP per capita, we can see the trend is there and is pretty much strong.
This constant productivity increase over the time is what allows us to work less and make more money.
Things will still change
So, everything will stay the same? Well, no. Of course AI will have an impact in the job market. But the change might be more related to jobs migrating from one industry to another, and from one region to another.
The European Central Bank study [2] suggests that increases in productivity move jobs in two main ways:
less manufacturing jobs, more services jobs
less low-skill jobs, more high-skill jobs
More specifically, we expect more jobs in health, education, and services, and less jobs in utilities, mining, and construction.
Also, in the meta-analysis we saw earlier [1], they identify five key categories of technology measures in the literature, with different impacts on job markets:
Information and communication technology: more high-skill, non-routine, and service jobs;
Robots: the negative impact on employment is generally offset by new jobs related to their production, operation, and maintenance;
Innovation: product innovation seems to create jobs, but the evidence for process innovation remains mixed;
Productivity: job gains were mostly favorable for non-production, high-skill, and service jobs. Nonetheless, the net employment effects observed in these studies are rather negative than positive;
Other: other/indirect measures of technology indicate net job creation effects, particularly for non-production labour, but also for lowly skilled workers, particularly in service jobs.
So we could expect either:
relocation of jobs from manufacturing countries towards service-intensive countries;
a change in the sectorial structure within countries, with an increase of service jobs when compared to manufacturing;
a mix of both.
I imagine these changes could increase inequality due to:
the migration towards high-skill jobs, particularly if education doesn’t keep up;
more money going to capital owners: there is already evidence [2] that the share of labor on national income is decreasing.
We could be wrong, but how?
Of course this whole analysis could be wrong. Let’s try and gather some evidence that goes in the opposite direction, or at least understand in what ways the evidence we saw before could be inadequate.
There are some theoretical attempts to model the Marxist thesis of “labor immiseration”, looking at different axes:
Inter-generational market failure: quick advancements in technology benefit skilled workers and those who own capital in the short term. However, over time, it leads to hardships for people who cannot invest in physical or human capital;
Task encroachment: two opposing economic forces shape how much income goes to labor: technology advancement which replaces ‘old’ tasks, decreasing labor’s share of output, potentially lowering real wages; and internal technological progress that creates new tasks requiring labor. The interaction of these forces may result in a unbalanced growth path;
New tasks might not be created “fast enough”: the number of automated tasks could grow at a higher rate than the new tasks created by automation, leading to a reduction in the number of tasks that can be performed by humans;
These models are theoretical, though: they are not evidence that the net job losses will happen, they just outline scenarios where it could.
There is some evidence showing that this time could be different, and that this relationship between productivity and unemployment might be shifting: recent decades have witnessed more negative own-sector effects of productivity growth, especially in manufacturing, and less positive external effects on other-sector employment, possibly due to increased trade openness. However, this pattern has been seen before, in the 1980s, and it’s not new [2].
Another study, by the National Bureau of Economic Research [5], looks at the impact of increased industrial robot usage in the United States from 1990 to 2007 on local labor markets. The researchers find that the rise in robot usage leads to a significant negative effect on employment and wages across commuting zones. They support their findings by showing that areas most exposed to robots post-1990 did not display different trends before that period. The impact of robots is distinct from other factors like imports from China, decline of routine jobs, offshoring, and various types of IT capital. The conclusion suggests that for every additional robot per thousand workers, the employment to population ratio decreases by about 0.18–0.34 percentage points, and wages decrease by 0.25–0.5 percent. The study focuses specifically on industrial robots in certain local labor markets, which can’t account for the spillover effects on other regions or markets.
Maybe this time it’s different, and AI is such a disruptive technology that it will behave in a different way. Maybe, its relationship with productivity is different than other technologies.
Maybe. But the empirical evidence suggests otherwise, so I wouldn’t bet on it.