My top 10 book picks from 2024, to help you build your 2025 reading list
This year, for some reason, I found myself reading a lot more than usual — 52 books in total — without even pushing myself.
I think it happened naturally because I bought many books that genuinely interested me (I also tackled some really short ones, to be fair).
Here are some of the best books I read this year to help you build your reading list for 2025.
But before we dive in, you might be wondering why bother with this. Why create a reading list or read books at all? Well, reading is one of the best things you can do for yourself. There’s so much knowledge out there from experts in various fields — Nobel laureates, Harvard PhDs, and more. Books are affordable, and most of them are really enjoyable to read.
And why books? Why not just read blog posts?
A good book is like a painting: the author invests a lot of time, does extensive research, and works tirelessly to distill their ideas into the pages. That effort really shows.
Good books have layers and depth. Re-reading them reveals new insights each time.
This applies to both fiction and non-fiction. These days, self-development books are selling really well, partly because their titles are so straightforward: “How to Win Friends and Influence People,” “How to Talk to Anyone,” “Think and Grow Rich”.
There’s nothing wrong with that, but remember that many of those lessons can also be found in fiction, presented in a more friendly and subtle way.
Plus, reading doesn’t have to be just for learning — it can also be purely for fun!
Personally, I like to mix things up. This year, I read a lot of fiction, economics, and data science books.
Now, onto the list.
Less Technical Stuff
Build
Tony Fadell’s memoir and practical guide for entrepreneurs offers insights from his experiences designing iconic products like the iPod and Nest.
It’s a rare book written by someone who has actually built things. It covers everything from HR to marketing to legal issues and walks you through the different stages of building a business — from working on a product with a small team to managing an organization of over 400 people.
The Capitalist Manifesto
This book argues in favor of capitalism as the ultimate system for freedom, innovation, and wealth creation.
Contrary to popular belief, global free-market capitalism has been the main driver of prosperity, reduced inequality, and fostered innovation over the past few centuries.
While some of the author’s claims come across as naive and heavily biased toward capitalism (for example, suggesting capitalism has a net positive impact on the environment), most arguments are solid and backed by strong data. Absolutely worth reading.
The Chronicles of Narnia
A classic fantasy series by C.S. Lewis about children discovering a magical world full of adventure, talking animals, and profound moral lessons.
The seven books are an allegory of biblical stories, spanning from the creation of Narnia to its end. Remember Aslan, the talking lion from the movies? He symbolizes God, which is made very clear in the books, as he serves as a benevolent and just king/father figure.
Though I’m not religious, I found it fascinating to see the lessons built into the narrative. Regardless of your beliefs, many of these lessons are universal, and reading these books with your children can be a great way to pass those values on.
Educated
Tara Westover’s memoir chronicles her journey from an isolated, fundamentalist upbringing to pursuing education and self-discovery. I couldn’t put it down.
Tara’s parents were extreme conspiracy theorists who refused to send their kids to school or take them to the hospital, believing these institutions were part of a larger scheme to control people. While their worldview might seem absurd at first, it’s heartbreaking to see its impact on their children.
Despite this, Tara managed to escape that environment and eventually earned a doctorate from the University of Cambridge. Safe to say, she turned out okay.
The Power of Creative Destruction
This book explores how innovation drives economic growth and progress by disrupting and replacing outdated systems.
For me, the main takeaway is that demonizing either free-market competition or state intervention doesn’t make sense. Both are necessary, and the book does a great job explaining when government intervention is helpful and when it can cause more harm than good.
Factfulness
This book illustrates global progress by plotting GDP per capita against life expectancy and categorizing countries into four development levels along this axis.
Interestingly, most countries fall in the middle, with only a few being extremely poor or very rich. Almost all countries, however, are moving in the right direction.
It’s remarkable how life has improved globally over the past 100 years. What’s even more surprising is how wrong people often are about the current state of the world. The author surveyed people worldwide, asking specific questions about statistics like vaccination rates, and the results showed widespread pessimism.
This negativity is partly due to the media’s tendency to focus on bad news. While the world isn’t perfect, things are steadily improving, and this book is a great reminder of that.
More Technical Stuff
Fundamentals of Software Architecture
Especially with the rise of generative AI, we’re often asked to build tools that don’t require much data science — just smartly calling APIs and wrapping them in a Streamlit interface.
This calls for a better understanding of software architecture.
All data scientists can benefit from learning software architecture principles. We tend to focus heavily on coding without understanding how our work fits into larger systems. This book offers a comprehensive guide to designing better systems.
Clean Code
A practical guide to writing clean, maintainable, and efficient code, this is a classic in the field.
It’s particularly useful for data scientists like me, who learned coding through Jupyter notebooks and picked up some bad habits along the way. Trust me, clean code matters — it improves readability and reduces bugs.
While it’s a great book, much of it could be distilled into a list of dos and don’ts (which I might create in a future story). However, keep in mind it’s very Java-specific.
System Design Interview
This preparation guide for system design interviews explains frameworks and best practices in a clear, concise way, making it easy to understand.
It’s a great starting point for learning system design concepts, regardless of whether you actually have an interview coming or not.
Causal Inference in Python
This hands-on guide shows how to apply causal inference methods using Python for real-world data science problems.
It borrows heavily from econometrics, so it’s an excellent resource if you come from that background. If your prior exposure to causality has been through machine-learning-focused sources, this book provides a refreshing new perspective.
How can we apply statistical methods to real-world problems?
Who should read this book?
You either work with data or want to start to, but come from a tech background or just don’t remember much from Stats 101, and need a refresh on the basics of statistics.
One-paragraph summary
It’s a good starting point to understanding statistics: it approaches a broad range of topics, from basic probability to random forests, without going too deep in any of them, so no previous mathematical background is required.
Full summary
Introduction
The author starts by giving a series of possible definitions for statistics, one of them being “the technology of extracting meaning from data”.
“Statistics is hocupocus with numbers” — Audrey Habera and Richard Runyon
He then gives a glance of the many different applications that are possible with statistics, from public policy to marketing to spam filtering, and mentions some of the issues that can arise from misusing it. The most notable example is the Sally Clark case: in 1999, a young British lawyer was sentenced for life for killing her two baby children who she claimed had died from cot death. The sentence was based on the testimony of Sir Roy Meadow, the prosecution’s paediatrician, that said that it was nearly impossible that this was the actual cause, since the chances of this happening to two children was of 1 in 73 million. The verdict was then that the mother was guilty. The probability calculated by the doctor was, however, flawed: he did it by multiplying the probability of one cot death two times. This method, however, needs the two events to be independent, which they are not, considering that, given that one of the children died from it might indicate genetic conditions that will also manifest in the second child.
This, and many other examples, show that statistics has an important role in society: providing evidence. Without it, we cannot subject our opinions to test, and they remain mere speculations.
Statistics began on the end of the 19th century only as discursive explorations of data. In the first half of the 20th century it evolved and became a more mathematics-oriented field. Only in the second half of the 20th century it faced its latest revolution with the use of computers, which allowed the field to develop its methods and apply heavy-computational algorithms.
Descriptions
In statistics, we analyse objects and their attributes usually in the shape of observations and variables. This information can, sometimes, be overwhelming, so we might want to aggregate it by doing simple summary statistics: average, dispersion, skewness and quantiles, for example.
The concept of average can comprise many formal concepts, but the most used case is the arithmetical mean: the sum of all values, divided by the number of observations. For example, if we wanted to understand the attribute “age” for a given classroom of college students, instead of looking at all the students’ ages, we sum them all, divide by the number of students, and get 22 years. It doesn’t mean all students are 22 years old, but it gives us an overall picture: some are older, some are younger, but we can imagine it is not a classroom full of kids, for example.
However, let’s take a second example: there’s five people, four of them earn $5,000 a month and one of them earns $100,000 a month. In average, these people make $24,000 a month. However, this does not fully describe their real situation, since it is not a group of people where everyone earns more or less $24,000. From here we can add the concept of dispersion: how far from the average are the values in this group? One measure of dispersion is the variance, calculated by taking the square of the difference between all the numbers and the mean, and then calculating their averages. Wouldn’t it be simpler to just take the mean without the square part? Yes, but then positive and negative values would reduce each other’s effects, cancelling out the whole purpose of measuring dispersion. We can take the square root ofthe variance as another measure, called the standard deviation.
Ok, so we know the average and whether the dispersion is high or low, but how exactly is the shape of this dispersion? For this, we can look at skewness and quantiles. Skewness measures the lack of symmetry in the population: if it’s very asymmetric, there are many more values higher or lower than the average. Quantiles tell you what value you should take if you want a certain percentage of the population below this value, and there are a few types of quantiles. One of the most common is the percentile: if you are in the 90th percentile of your classroom’s grades, it means you have better grades than 90% of the your classroom.
Collecting good data
“Garbage in, garbage out” — Everyone data science article out there
When collecting data for analysis, it is very important to pay attention to its quality: no matter how sophisticated are your models, if you put bad data in, your outcome will also be poor.
Pay special attention to missing data: sometimes it’s random but sometimes it can also reveal an underlying pattern. For example, when asking people for their income, people who get really good (or really bad) salaries may prefer not to answer, generating missing data that can actually give you some information. To deal with missing data, you can ignore it, remove those observations/variables or you can try to input it by replacing them by something simple such as the sample mean or by something a lot more complex, using prediction algorithms. It will depend mostly on your data and your goals. When data is incorrect, on the other hand, most of the time there’s not much that can be done a posteriori so avoid making these mistakes when fetching data.
When it comes to data sources, they can basically be of two types: observational or experimental. The first one comes from real-life observations whereas the latter comes from controlled experiments. Experimental studies are better for isolating variables and causation effects but they are usually harder to do. When conducting experiments, we should plan very well our experiment design: choosing the best groups for measuring the impact of each variable, taking into account the effect of interactions. For example, if we want to test the effect of a new drug, we should have a control group and a test group, sampled randomly from the population, ideally with similar characteristics. If the test group has only men and the control group has only women, we won’t be able to know if the observed results were the effect of the drug or of the subject’s gender.
For this kind of procedure, we can apply techniques from a statistics domain called survey sampling, which can help us the best methods of sampling individuals within a population.
Probability
Another definition of statistics is “the science of handling uncertainty”, which is what the study of probability tries to address. A lot of its utility is based on the Law of Large Numbers, which roughly means that, if when you toss of a coin you have 50% chances of getting heads, then the more you throw the coin, the closer the overall proportion of heads will be to 50%.
This leads us to the two main approaches when it comes to probability: frequentist and Bayesian. Roughly, frequentists see probabilities as the proportion of times the event would occur if the exact same circumstances were repeated infinitely. The Bayesian approach takes into account the amount of information available: probability is subject to how much we know, and thus it changes as we gather new information.
Whatever approach you take, you will encounter the idea of independence between events. Basically, two events being independent means that the occurrence of one of them does not affect the probability of the other one occurring. If we throw two coins separately, the fact that we got heads in one does not change the probability of getting heads in the second one.
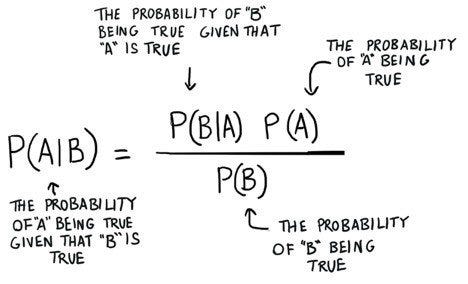
To look at dependent events, we often use the Bayes theorem, which is given by the formula below:
Ok, that’s very useful, but how do we know these probabilities? In basic exercises, usually we have probabilities that are easy to calculate, with things such as coins and dice. But how do we deal with more complicated probabilities? We work with cumulative distribution functions, which give us the probabilities of finding a value smaller (or greater) than another value we set. For example, if we knew the distribution of people’s heights in our town, we could calculate the probability of finding someone shorter (or taller) than 1.80m. From this function, we can derive the probability distribution, that gives us the probability that a value will fall within a certain range (we could know the probability of someone being between 1.70m and 1.80m tall, for example).
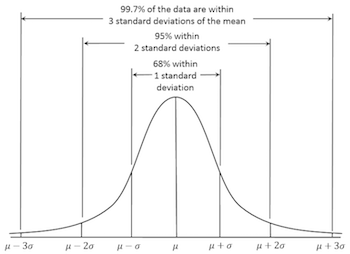
Some distributions are particularly important since they are often found in many real-life phenomena: Bernoulli, Binomial, Poisson and Gaussian, to mention a few. The Gaussian distribution is particularly important because of the Central Limit Theorem that states that, for any given distribution, when we sample the population many times, the means of those samples will follow a Gaussian distribution with the same mean as the original population.
Gaussian distribution. Source: Wikipedia
Probability distributions are a huge subject, and there’s a lot of content out there on it. It is out of the scope of the book to go into the details of each of them but it’s an interesting subject to study further.
Estimation and inference
Once we have our probability distribution, we want to be able to make estimations from a given sample. For example, let’s say we sample a few students in a school, get their ages and want to estimate the average age in the school. There are mainly two approaches to it: Maximum Likelihood and Least Squares. The first one reasons that our estimation of the average age in the population should be the one that makes the sampled result the most likely. The latter tries to find the estimation that will yield the smaller difference between estimated values and observations. And how do we choose an estimator? Ideally, we want an unbiased estimator, such that it is expected to give us a true result, but also one that doesn’t vary too much depending on the sample we take.
What if we want to estimate an interval, instead of a single point? It is also possible, due to something called confidence interval. A confidence interval can be calculated from the distribution we have, and will allow us to make a statement more or less like “I’m 95% confident that the average age in this school is between 10 and 12”, which can be quite useful for decision-making.
Another important statistical method is called hypothesis testing, which is used to test if your parameter takes a specific value or lies within a specific range. Let’s say we want to know if men and women earn the same. We sample a group of men and a group of women, calculate their average wages and find out that men earn in average $35,000 a year and women make $33,000. Ok, can we really say that those populations are essentially different? What if women earned $34,999, could we also reach the same conclusion? How big should this difference be so that we can say its statistically significant? We set a level of confidence we want to have (say 95%) and test our hypothesis. There are many ways of doing it, depending on what we are testing and on the population distribution but, if we do it right, our test will indicate us if our hypothesis holds or not.
Statistical models
A statistical model is some simple representation or description of the system we are studying. Since it is a simplification, we’ll necessarily lose information in this process, so we try not to lose the most important bits.
“All models are wrong, some models are useful” — George Box
Models can be mechanistic, based in a solid underlying theory (such as gravity) that allows us to predict some behaviour (an object falling, for example) or empirical, more common in the social sciences, where we try to infer the theory from observed data.
They can also be exploratory, where we try to find relationships and patterns (ex.: looking at demographic data to see if there are characteristics that are correlated) or confirmation models, where we test our conjectures to see if they are supported by data.
Finally, they can be split into descriptive models, where we try to characterise our data, calculating means, standard deviations, etc., or predictive models, were we try to infer some variable’s behaviour based on the other variables.
Predictive models are quite useful and they can be very simple or very complicated, usually depending on the number of explanatory variables we use. However, more complicated models do not always yield better predictions. Sometimes, adding more information makes models so specific for our sample that they do not generalise well for the whole population. This phenomenon is called overfitting.
Statistical models are often based on the idea of correlation: when two variables are correlated, it means that observing a value for one of them gives us a hint on the value of the other. For example, height and weight: tall people tend to be heavier and heavy people tend to be taller. Obviously, tall people can be light and heavy people can be short, but there’s still an overall trend. Correlation can also be negative, for example temperature and hot chocolate sales: the higher the temperature, the less people buy hot chocolate. Correlation is usually represented by a correlation coefficient that goes from -1 (perfect negative correlation) to 0 (no correlation at all) to 1 (perfect positive correlation). It is very important to keep in mind that correlation does not mean causation. For example, ice cream sales and deaths by drowning are correlated, but one does not cause the other, it’s just that in warmer days people buy more ice cream and swim more, so usually when ice cream sales go up it’s because it’s a warm day, meaning more people will swim (and drown).
In the end, the author briefly goes through some important statistical methods that are worth checking in more detail:
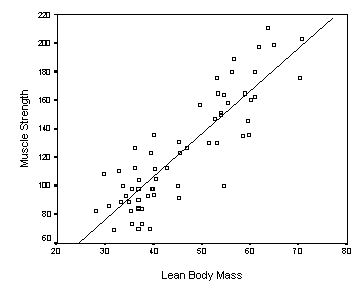
Regression analysis: it allows us to say “someone who weights 83kg is expected to be 1.83m tall”, based on a sample, even if we haven’t sampled anyone who’s 83kg. The most basic type of regression is linear regression, which supposes a linear relationship between two variables, as per the example below:
In the plot above, we can see our sample data (the dots) and the estimated regression line that will allow us to make estimations.
Analysis of variance (ANOVA): it allows us to compare means from many different populations and test if they are significantly different or not.
Clustering: used for finding groups of observations that are very similar. We just set the number of groups we want in the end and the algorithm gives us the best partitions.
Linear Discriminant Analysis (LDA): technique for finding the best linear combination of features in order to characterise different observations. Roughly, it helps us find attributes that are good at differentiating observations.
K-nearest neighbours (KNN): method used to estimate an attribute of a specific observation, based on the K observations that are the most similar to it.
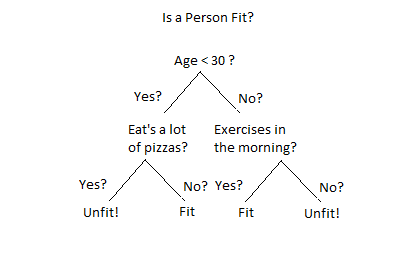
Decision tree: it is a very intuitive model used to estimate a certain characteristic (numeric or not) for a given variable, based on decision rules:
Time series: there is a whole domain in statistics dedicated to studying how certain variables fluctuate on time, based on concepts like trend and seasonality.
Factor analysis: in summary, it tries to find factors that are responsible for the shared variance between the observed variables.
Cross-validation: to avoid overfitting, we should not test our models on the same data they were trained on. There are many different methods that allow us to do that, such as splitting our sample data into two groups, one for training and one for testing.
Bootstrapping: it’s a good technique for getting better models, by sampling observations and replacing them within the actual sample.
Survival analysis: for example, imagine studying impacts of a disease in people’s lifetimes. After 20 years of study, some people have died, some haven’t. How do you deal with those who didn’t die, since you do not know their total lifetime yet? If you remove them from the study, you remove everyone who survived, and you will estimate a lifetime shorter than it actually is. Survival analysis deals with this sort of specificity.
Statistical computing
With the advent of computers, most of the calculations needed for statistical analysis can be done within seconds with softwares such as R, which really helped this field to grow, and made statistician’s work a lot easier and more productive. On the other hand, it made it easier to apply methods without mastering how they actually work, leading sometimes to wrong results.
Conclusion
The book really covers a broad range of subjects, so of course it is not possible to go too deep in any of them. However, it’s a very good introductory book, specially for those who come from a non-mathematical background. It is important, though, to pick some subjects that seem more relevant to you and study them in more depth. I’ll give it 7/10.
Building full-stack data analytics applications with Spark
Who should read this book?
You are already a Python experienced user, with some knowledge in Spark, and you want to fill your knowledge gaps while building a full data science application from scratch with a front-end interface.
One-paragraph summary
The book is a step-by-step guide on how to build an application for analytics, including downloadable scripts. It will give you an initial overview of the Agile method, and how to apply it to data science, but 80–90% of the book will be hands-on tutorials. In the end, you should have built an HTML page that estimates delays for a given flight, gathering data from different sources.
Full summary
This book is basically a big tutorial, and since there is no point summarising a tutorial, the summary will focus only on the more general parts that talk about agile and data science.
“Agile Data Science is an approach to data science around web application development” — The book
In addition to what the above quote says, the author starts the book by defining Agile Data Science as “a methodology for analytics products development, mixing the best software development practices, but adapting them to the iterative nature of data science”.
The Agile Data Science Manifesto
One of the key steps towards Agile Data Science is constantly shipping intermediate output: no matter if something is still a draft or you are not sure the data is correct, ship it to your internal user for validation. This will avoid wasting time on features people do not need, and will also help you spot issues early on. This also means documenting the whole thinking process and not just the final product.
That kind of process will also help reducing technical debt, defined as “a concept in programming that reflects the extra work that arises from building code that is easy to implement in the short run, instead of using the best overall solution”.
Since data science development is a very iterative process, it is impossible to determine deadlines beforehand. Instead, agree beforehand with you stakeholders that you cannot give them a precise final date, but that will you ship constant progress reports. These reports do not have to be actual formal reports, but a front-end interface that shows the current shape of your data, which will also help you get constant feedback.
People management
“In Agile, we value generalists over specialists” — Also the book
In a standard data science project, there can be several roles, one for each step of the process. In Agile, we try to make the team leaner, by getting generalists instead of specialists. In general, this means we want someone to be a business developer, marketer, and product manager at the same time, someone else can be the experience designer, interaction designer, and web developer, then a third person can take over the roles of an engineer, data scientist, and researcher, and finally someone to be both a platform engineer and a DevOps Engineer. This means 4 people doing the job of 11. Although there are less people involved, there is a lot of synergy between these functions, so we compensate in productivity.
For this setup to work, it is better to use third-party high-level tools and platforms, instead of developing everything in-house. It will save you a lot of overhead time, so you can focus on what really matters.
If you manage a data science team, focus more on overseeing all the experiments that are happening simultaneously throughout the team, than in handing tasks for each one.
Finally, make sure your developers share their code with each other for peer-review, or code together. This will help finding errors and making code more readable for future users.
Agile tools
The typical data flow comprises at least 5 different types of tools, used in a sequential order.
Collectors: the tools used to collect and log events (events are the occurrences we want to measure, such as clicks and purchases). Ex.: Kafka
Bulk storage: filesystem capable of parallel access by many concurrent proceses. Ex.: Amazon S3 and Hadoop (companies are more and more using Amazon S3 instead of Hadoop).
Distributed document stores: multi-node stores using a document format. Ex.: MongoDB
Application server: it plumbs JSON files from the distributed document store through to the client, allowing for visualisation. Ex.: Python/Flask, Ruby/Sinatra, Node.js.
Browser/application: it displays data visualisation and possibly interactive tools. It can be a dedicated app or an ordinary internet browser, to display HTML pages.
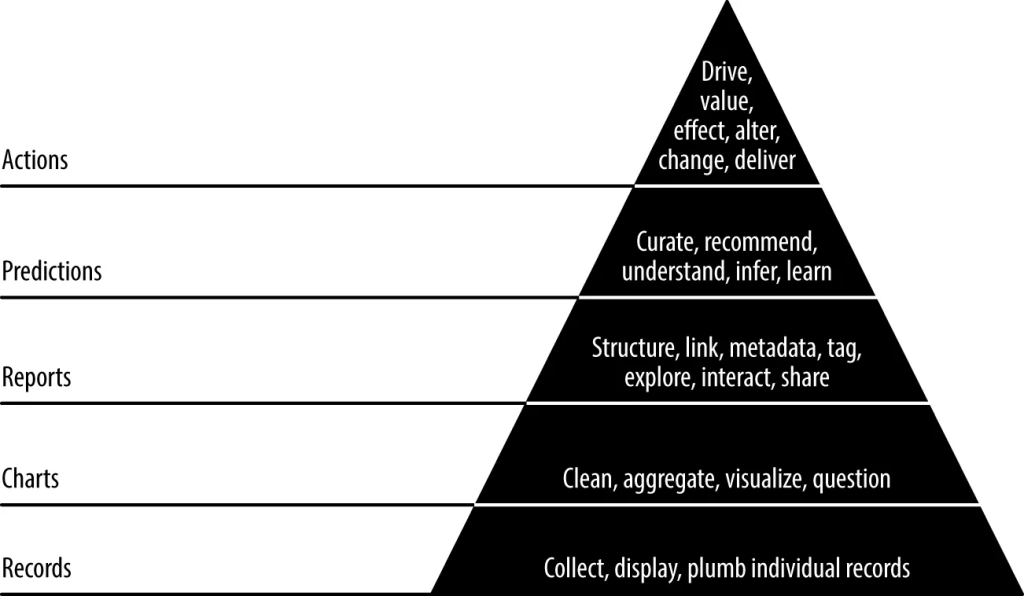
The Data-Value Pyramid
The Data-Value Pyramid shows all the added-value we can get from data in a shape that highlights the importance of foundations: you cannot optimally get value from your reports, for instance, if you have not yet worked properly on plumbing your records and displaying basic charts. This is valid from a project perspective, but also from a company’s point of view: companies should have solid foundation on how their records are collected, and sound understanding of basic charts before moving on to building reports or trying to implement recommendation systems. This process allows for constant iteration in each step before moving on to the next. The project built in the book is based on these steps, with the author detailing each of them with examples:
Records
These are the foundation of your pyramid: make sure you are collecting exactly the events you want and make many tests to check for inconsistencies. Then, display those records in a front-end interface and exchange with your stakeholders. This will help you see if you are working with the right data and avoid wasting time in the future.
Charts
Charts are the first and simplest way to have proper visual representation of your data. You probably won’t be able to get your charts right at first, so try different approaches and iterate with the feedback you get. In the end, make sure your chart tells a story.
Reports
Reports are a set of charts or tables and other additional information, eventually with interactive features. Make sure you know the kind of information your end users need by exchanging information, and understand how they interact with your report, so you can choose the interactive features. They can be built from the charts you already have.
Predictions
“Prediction is very difficult, especially if it’s about the future” — Nils Bohr, Nobel laureate in Physics
Here is where the value of data starts showing: seeing what happened in the past is good, but being able to predict the future is great. The example used in the book is a model that tries to predict flight delays based on time of departure, airport and even aircraft information. There are essentially two types of prediction models out there: regression and classification. Roughly speaking, regression deals with problems where you will have a quantitative output in the end, such as predicting a house price or someone’s weight, whereas classification deals with categorical outputs: predicting someone’s football team or social class.
Actions
Finally, this is the most important part: information is only worth something if you can act on it. The book does not describe this step, but it could have been a good idea to give some examples of direct action originated by data science. Instead, it ends by improving its predictive model. It is very important to know what actions you will take based on your prediction data, ideally before calculating it. This helps you avoid “vanity metrics”: metrics you look at to feel good but don’t help you make any decisions.
Conclusion
Since all the code comes with the book, it is very easy to just sit back and follow the script, which won’t help you a lot. Instead, try to not only run the scripts but to understand them and, eventually, change and adapt them for your personal use cases. Without the coding part, there is actually not much content left in the book, so the name can be a bit deceiving: you get this very specific tutorial without much explanation on Agile and/or Data Science. It is a good book to have around in case you need some ideas for a data application setup, but nothing you cannot find online with a bit of effort. I’d give it a 6/10.
P.S. Make sure you have 16GB of RAM or are willing to pay for a virtual machine in AWS, otherwise you will not be able to follow through.