How Meta made AI even closer to how humans think
Traditional language models (LLMs) process text one word at a time.
They predict the next token based on the ones before it.
That works well, but it’s not how humans think.
When we write or speak, we don’t just string words together.
We organize our thoughts into sentences, ideas, and concepts.
That’s where Large Concept Models (LCMs) come in.
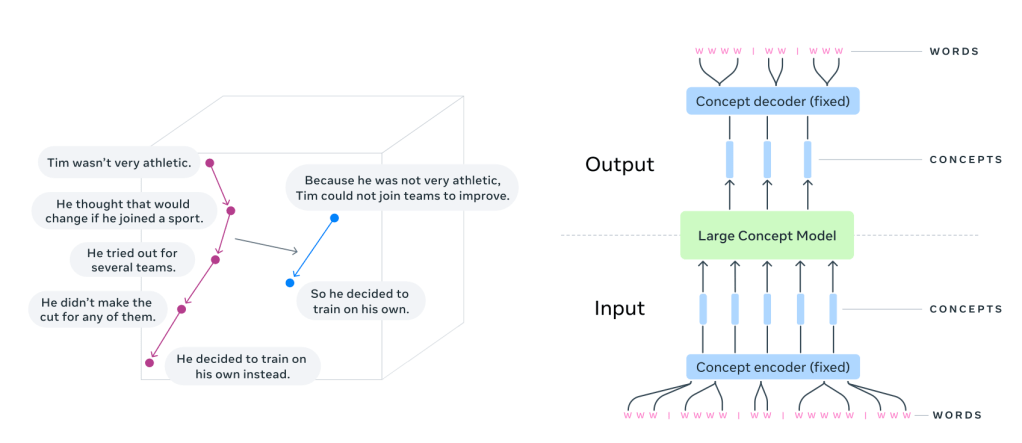
Instead of predicting the next word, LCMs predict the next sentence.
Each sentence is treated as a concept — a standalone unit of meaning.
That’s a big shift.
Why does this matter?
LLMs operate at the token level, making them great at text generation but limited in their ability to reason hierarchically. They tend to get lost in long-form content, struggle with consistency, and often fail to keep track of structured ideas.
LCMs take a different approach. They generate text in sentence embeddings, operating in a high-dimensional space (like SONAR) instead of token sequences. Instead of focusing on words, they predict thoughts in a way that’s language- and modality-agnostic.
This has big implications:
- Better context understanding — By modeling entire sentences as units, LCMs improve coherence and logical flow.
- Multilingual and multimodal — Trained on 200+ languages, LCMs can generalize across text and speech without additional fine-tuning.
- More efficient generation — Since they work at a higher level, they process fewer steps, making them faster and more scalable than token-based models.
- Stronger zero-shot performance — LCMs outperform LLMs of the same size in summarization and text expansion tasks, even in languages they weren’t explicitly trained on.
The technical shift
LLMs generate text autoregressively, predicting one token at a time. This requires them to process long token sequences and maintain coherence through implicit context modeling.
LCMs, on the other hand, predict the next sentence embedding in a latent space.
Instead of raw tokens, they work with sentence representations from SONAR, a multilingual embedding model.
SONAR is trained to encode and decode sentences across 200+ languages into and out of a single shared representation space. When an LCM needs to handle a new language or modality, only the SONAR encoder/decoder must be updated — leaving the central model untouched.
The embeddings are processed autoregressively using diffusion models, MSE regression, or quantized representations — allowing LCMs to generalize across languages and modalities without needing explicit tokenization.
This shift reduces computational complexity, makes it easier to edit long-form text, and allows AI to reason at a higher level of abstraction.
The results
When tested on summarization and summary expansion, LCMs outperformed traditional LLMs of the same size.
They showed strong generalization across multiple languages — without additional fine-tuning.
They handled long-form text more coherently than token-based models.
And because they work in a modular embedding space, they can be extended to new languages, speech, or even sign language, without retraining the entire model.
Challenges
Sentence splitting
LCMs rely on robust sentence segmentation. Very long or tricky “sentences” can hurt performance.
Out-of-distribution embeddings
With MSE or diffusion, the model could predict vectors that don’t perfectly map back to valid text. Diffusion or well-tuned quantization helps mitigate this.
Averaging vs. sampling
A purely MSE-based approach might average all potential continuations into a single “blurry” embedding. Diffusion or discrete codebooks allow multiple plausible completions.
The Future of Language Modeling?
LLMs work. But they are word-by-word prediction machines.
LCMs take a different path — one that focuses on thoughts, not just tokens.
By modeling language at the concept level, they bring AI closer to how humans structure ideas.
This isn’t just an optimization. It’s a fundamental shift in how AI understands and generates language.
And it might just change how we build the next generation of intelligent systems.
Link to the original paper: https://arxiv.org/abs/2412.08821
Feel free to reach out to me if you would like to discuss further, it would be a pleasure (honestly):

Leave a comment